Многомерный
стационарный случайный процесс определяется как совокупность стационарных и
стационарно связанных между собой случайных процессов ![]() . Такой процесс принято
обозначать в виде случайного вектора-столбца, зависящего от времени:
. Такой процесс принято
обозначать в виде случайного вектора-столбца, зависящего от времени:
![]() .
.
Многомерные случайные процессы используются при описании многомерных (многоканальных) систем. В настоящем параграфе рассматривается задача цифрового моделирования нормальных многомерных стационарных случайных процессов. Результатом решения этой задачи, как и в одномерном случае, является алгоритм, позволяющий формировать на ЦВМ многомерные дискретные реализации заданного процесса. -мерный непрерывный нормальный стационарный случайный процесс задается обычно либо в виде его корреляционной матрицы
![]()
либо в виде спектральной матрицы
![]()
где -
автокорреляционные
(при ) и
взаимно корреляционные (при ) функции случайных процессов - преобразование
Фурье от .
При этом, поскольку ![]() ,
элементы и спектральной матрицы
комплексно-сопряженные,
,
элементы и спектральной матрицы
комплексно-сопряженные,
![]() .
.
Дискретные многомерные нормальные случайные процессы задаются аналогично непрерывным с помощью корреляционных и спектральных матриц (35, 70]

где  , причем
, причем ![]() .
.
Задачу цифрового моделирования многомерного нормального случайного процесса целесообразно сформулировать следующим образом. Задана корреляционная или спектральная матрица случайного процесса. Требуется отыскать алгоритм для формирования на ЦВМ дискретных реализаций случайного процесса с заданными корреляционными (спектральными) свойствами.
Для решения этой задачи воспользуемся, как и ранее, идеей формирующего линейного фильтра. В рассматриваемом случае речь идет о синтезе многомерного формирующего фильтра.
Мерный
линейный фильтр определяется как линейная динамическая система с входами и выходами . Если ![]() - входное воздействие
и
- входное воздействие
и ![]() - реакция
системы, то связь между входом и выходом -мерного линейного непрерывного фильтра
описывается с помощью передаточной матрицы в виде
- реакция
системы, то связь между входом и выходом -мерного линейного непрерывного фильтра
описывается с помощью передаточной матрицы в виде
![]()
где ![]() и -
изображения
входного и выходного сигналов соответственно в смысле преобразования Лапласа;
и -
изображения
входного и выходного сигналов соответственно в смысле преобразования Лапласа; ![]() -
передаточная
матрица -мерного
фильтра, у которой элементы являются передаточными функциями каналов -й вход - -й выход.
-
передаточная
матрица -мерного
фильтра, у которой элементы являются передаточными функциями каналов -й вход - -й выход.
Аналогично описывается связь вход - выход в дискретных -мерных линейных фильтрах:
![]() ,
,
где и - изображения в смысле дискретного преобразования Лапласа входного и выходного сигналов; - передаточная матрица дискретного -мерного фильтра.
Структурная схема многомерного фильтра на примере двумерного фильтра приведена на рис. 2.9, согласно которому
 (2.107)
(2.107)
Видим, что каждый из выходных сигналов и является суммой линейных операторов от входных сигналов и . Аналогичные соотношения имеют место и в общем случае. В этом и состоит идентификация передаточных матриц .
Пусть воздействие на входе -мерного линейного фильтра представляет собой -мерный белый шум, т. е. случайный процесс с корреляционной матрицей вида
для непрерывного времени и
для дискретного
времени, где ![]() - дельта-функция. -мерный белый шум
определен здесь как совокупность независимых между собой -коррелированных
случайных процессов.
- дельта-функция. -мерный белый шум
определен здесь как совокупность независимых между собой -коррелированных
случайных процессов.

Можно показать (см., например, ), что при воздействии белого шума спектральная матрица процесса на выходе - мерного фильтра для непрерывного и дискретного времени соответственно связана с передаточной матрицей фильтра соотношениями
 (2.108)
(2.108)
где символом обозначена транспонированная матрица.
Следовательно, для получения -мерного случайного процесса с заданной спектральной матрицей нужно пропустить -мерный белый шум через -мерный формирующий фильтр, передаточная матрица которого удовлетворяет уравнениям (2.108). Для нахождения передаточной матрицы по заданной спектральной матрице требуется разбиение последней на два сомножителя вида (2.108). Эта процедура называется факторизацией спектральных матриц. Она может быть реализована по известным алгоритмам .
Многомерная
фильтрация белого шума осуществляется достаточно просто: каждая составляющая ![]() случайного процесса на выходе -мерного фильтра с передаточной
матрицей получается
путем суммирования по составляющих
случайного процесса на выходе -мерного фильтра с передаточной
матрицей получается
путем суммирования по составляющих
![]() входного
процесса ,
профильтрованных одномерными фильтрами с передаточными функциями [см. формулу (2.107)].
Алгоритмы одномерной фильтрации рассмотрены выше.
входного
процесса ,
профильтрованных одномерными фильтрами с передаточными функциями [см. формулу (2.107)].
Алгоритмы одномерной фильтрации рассмотрены выше.
При данном способе моделирования возможны два пути: 1) заданную спектральную матрицу непрерывного -мерного случайного процесса можно непосредственно подвергнуть факторизации для получения передаточной матрицы непрерывного формирующего фильтра, а затем, используя описанные выше точные или приближенные методы дискретизации непрерывных, фильтров, осуществить многомерную фильтрацию непрерывного белого шума; 2) по заданной спектральной матрице непрерывного -мерного процесса , используя -преобразование, можно найти спектральную матрицу соответствующего дискретного случайного процесса (см. § 2.3), далее путем факторизации найти передаточную, функцию дискретного формирующего фильтра, а затем произвести многомерную фильтрацию дискретного белого шума.
Наибольшие трудности встречаются при факторизации спектральных матриц. В настоящее время разработаны алгоритмы факторизации лишь рациональных спектральных матриц, т. е. таких матриц, элементы которых являются дробно-рациональными функциями аргументов или .
Опишем, опуская доказательства, один из алгоритмов факторизации рациональных спектральных матриц, взятый из .
Пусть задана рациональная спектральная матрица
 .
.
Матрица может быть приведена к виду
путем следующих преобразований.
1. Определяется ранг матрицы , затем один из главных миноров порядка располагается в левом верхнем углу матрицы .
2. Матрица приводится к диагональному виду. Для этого к -й строке матрицы , , прибавляется первая строка, умноженная на - , затем к -му столбцу прибавляется первый столбец, умноженный на ; получается матрица
 , (2.109)
, (2.109)
где элементы матрицы

имеют вид
![]() (2.110)
(2.110)
С матрицей проделываются те же
преобразования, что с исходной матрицей ![]() . При продолжении этого процесса на -м шаге получается
диагональная матрица
. При продолжении этого процесса на -м шаге получается
диагональная матрица
![]()
такая, что ![]() .
.
3. Находится вспомогательная матрица
![]()
элементы которой имеют следующий вид:
 (2.111)
(2.111)
где определяются из рекуррентных соотношений
 (2.112)
(2.112)
4. Находятся вспомогательные полиномы
![]()
где ![]() - нули полиномов
- нули полиномов ![]() , лежащих в нижней
полуплоскости, считаемые столько раз, какова их максимальная кратность, причем - знаменатели
дробно-рациональных функций, представляющих собой элементы матрицы :
, лежащих в нижней
полуплоскости, считаемые столько раз, какова их максимальная кратность, причем - знаменатели
дробно-рациональных функций, представляющих собой элементы матрицы :
![]() .
.
5. По способу, рассмотренному в § 2.9, п. 2, дробно-рациональные функции

представляются в виде
 ,
,
где полиномы и не имеют нулей в нижней полуплоскости.
На этом процесс факторизации заканчивается. Окончательно передаточная матрица формирующего фильтра записывается в виде
 (2.113)
(2.113)
Здесь описан алгоритм факторизации рациональных спектральных матриц непрерывных многомерных процессов. Факторизация спектральных матриц дискретных процессов осуществляется аналогично, только вместо корней, расположенных в нижней полуплоскости, берутся корни, расположенные в единичном круге.
Пример 1. Пусть задан двумерный непрерывный стационарный центрированный случайный процесс с корреляционной матрицей
 , (2.114)
, (2.114)
где - некоторые
положительные константы, причем ![]() .
.
Корреляционная матрица, соответствующая спектральной матрице (2.114), имеет вид
 , (2.115)
, (2.115)
где ![]() и
и ![]() - автокорреляционные
и взаимно корреляционный моменты процессов и соответственно; - коэффициент взаимной
корреляции процессов и
совпадающие
моменты времени. Коэффициенты и представляют собой в данном
случае ширину (на уровне 0,5) энергетических спектров
- автокорреляционные
и взаимно корреляционный моменты процессов и соответственно; - коэффициент взаимной
корреляции процессов и
совпадающие
моменты времени. Коэффициенты и представляют собой в данном
случае ширину (на уровне 0,5) энергетических спектров ![]() и взаимного энергетического
спектра процессов
и .
и взаимного энергетического
спектра процессов
и .
Требуется произвести факторизацию спектральной матрицы (2.114) для получения передаточной матрицы формирующего фильтра.
Будем осуществлять процедуру факторизации поэтапно в соответствии с приведенным выше алгоритмом факторизации.
1. В данном случае ранг спектральной матрицы .
2. Для приведения матрицы к диагональной требуется один шаг. По формулам (2.109) и (2.110) получаем
 .
.
3. В соответствии с выражениями (2.111) и (2.112) вспомогательная матрица имеет вид

4. В рассматриваемом случае нужно найти лишь один вспомогательный полином . Для этого требуется найти корни знаменателя у элемента матрицы , т. е. корни полинома . Эти корни равны
Следовательно,
![]() .
.
5. На заключительном этапе требуется произвести факторизацию дробно-рациональных функций

В данном случае корни числителей и знаменателей у дробно-рациональных функций и легко вычисляются. Используя корни, лежащие в верхней полуплоскости (корни с положительными мнимыми частями), получим и к переменной :
 .
.
На рис. 2.9 показана структурная схема двумерного формирующего фильтра, на выходе которого образуется двумерный случайный процесс с требуемыми спектральными характеристиками, если на вход фильтра воздействует белый шум. Заменяя непрерывный двумерный фильтр соответствующим дискретным фильтром, получим алгоритм для формирования на ЦВМ дискретных реализаций двумерного случайного нормального процесса, т. е. дискретных реализаций двух стационарных и стационарно-связанных нормальных случайных процессов с экспоненциальными авто- и взаимно корреляционными функциями вида (2.115).
При другом подходе к синтезу формирующего фильтра нужно сначала найти спектральную матрицу соответствующего дискретного многомерного случайного процесса . В рассматриваемом примере эта матрица имеет вид
И матрицы (2.116).
Рассмотренный пример показывает, что факторизация спектральных матриц осуществляется сравнительно просто, если удается аналитически найти нули соответствующих полиномов. При факторизации спектральной матрицы непрерывного двумерного процесса это не представляло труда, так как для определения нулей требовалось решать только квадратные и биквадратные уравнения. При факторизации спектральной матрицы дискретного двумерного процесса были квадратные уравнения и возвратное уравнение четвертой степени, также допускающее аналитическое решение.
В других, более сложных случаях нули полинома не всегда удается найти аналитически. В этих случаях прибегают к численным методам решения уравнений - й степени. В общем виде процесс факторизации можно реализовать на ЦВМ как стандартную программу. Для этой цели кроме приведенного здесь могут быть использованы и другие алгоритмы факторизации .
Следует заметить, что все существующие в настоящее время алгоритмы факторизации спектральных матриц, вообще говоря, весьма трудоемки.
Модуль Многомерные разведочные технологии анализа STATISTICA (один из модулей продукта STATISTICA Advanced ) предоставляет широкий выбор разведочных технологий, начиная с кластерного анализа до расширенных методов классификационных деревьев, в сочетании с огромным набором средств интерактивной визуализации для построения моделей. В состав модуля входят:

В модуле Кластерный анализ реализован полный набор методов кластерного анализа данных, включая методы k-средних, иерархической кластеризации и двухвходового объединения. Данные могут поступать как в исходном виде, так и в виде матрицы расстояний между объектами. Наблюдения, переменные или/и наблюдения, и переменные можно кластеризовать, используя различные меры расстояния (евклидово, квадрат евклидова, городских кварталов (манхэттеновское), Чебышева, степенное, процент несогласия и 1-коэффициент корреляции Пирсона) и различные правила объединения (связывания) кластеров (одиночная, полная связь, невзвешенное и взвешенное попарное среднее по группам, невзвешенное, взвешенное расстояние между центрами, метод Варда и другие).
Матрицы расстояний можно сохранять для дальнейшего анализа в других модулях системы STATISTICA . При проведении кластерного анализа методом k-средних пользователь имеет полный контроль над начальным расположением центров кластеров. Могут быть выполнены чрезвычайно большие планы анализа: так, например, при иерархическом (древовидном) связывании можно работать с матрицей из 90 тыс. расстояний. Помимо стандартных результатов кластерного анализа, в модуле доступен также разнообразный набор описательных статистик и расширенных диагностических методов (полная схема объединения с пороговыми уровнями при иерархической кластеризации, таблица дисперсионного анализа при кластеризации методом k-средних). Информация о принадлежности объектов к кластерам может быть добавлена к файлу данных и использоваться в дальнейшем анализе. Графические возможности модуля Кластерный анализ включают настраиваемые дендрограммы, двухвходовые диаграммы объединений, графическое представление схемы объединения, диаграмму средних при кластеризации по методу k-средних и многое другое.

Модуль Факторный анализ содержит широкий набор статистик и методов факторного анализа (а также иерархического факторного анализа) с расширенной диагностикой и большим многообразием исследовательских и разведочных графиков. Здесь можно выполнять анализ (общий и иерархический косоугольный) главных компонент и главных факторов для наборов данных, содержащих до 300 переменных (модели большего объема можно исследовать средствами модуля (SEPATH)).
Анализ главных компонент и классификация
STATISTICA также включает программу для анализа главных компонент и классификации. Выходные результаты этой программы - собственные значения (обычные, кумулятивные и относительные), нагрузки факторов и коэффициенты факторных баллов (которые можно добавить к файлу входных данных, просмотреть на пиктографике и в интерактивном режиме перекодировать), а также некоторые более специальные статистики и диагностики. В распоряжении пользователя имеются следующие методы вращения факторов: варимакс, биквартимакс, квартимакс и эквимакс (по нормализованным либо первоначальным нагрузкам), а также косоугольные вращения.
Пространство факторов можно визуально просматривать "срез за срезом" на двух- или трехмерных диаграммах рассеяния с отмеченными точками данных; среди других графических средств - графики "каменистой осыпи", различные типы диаграмм рассеяния, гистограммы, линейные графики и др. После того, как факторное решение определено, пользователь может вычислить (воспроизвести) корреляционную матрицу и оценить согласованность факторной модели путем анализа остаточной корреляционной матрицы (или остаточной дисперсионной/ковариационной матрицы). На входе можно использовать как исходные данные, так и матрицы корреляций. Подтверждающий факторный анализ и другие, связанные с ним виды анализа, могут быть выполнены средствами модуля Моделирование структурными уравнениями (SEPATH) из блока STATISTICA Общие Линейные и Нелинейные Модели , где специальный Мастер подтверждающего факторного анализа проведет пользователя через все этапы построения модели.

В этом модуле реализован полный набор методов канонического анализа (дополняющий методы канонического анализа, встроенные в другие модули). Работать можно как с файлами исходных данных, так и с корреляционными матрицами; вычисляются все стандартные статистики канонической корреляции (собственные векторы и собственные значения, коэффициенты избыточности, канонические веса, нагрузки, дисперсии, критерии значимости для каждого из корней и др.), а также некоторые расширенные диагностики. Для каждого наблюдения могут быть вычислены значения канонических переменных, которые затем можно просмотреть на встроенных пиктографиках (а также добавить к файлу данных).

Этот модуль включает широкий набор процедур для разработки и оценки выборочных исследований и опросных листов. Как и во всех модулях системы STATISTICA , здесь могут быть проанализированы чрезвычайно большие массивы данных (за одно обращение к программе может быть обработана шкала, состоящая из 300 позиций).
Имеется возможность вычислять статистики надежности для всех позиций шкалы, интерактивно выбирать подмножества и проводить сравнение между подмножествами позиций методом разбиения пополам ("split-half") или на две части ("split-part"). За одно обращение можно оценить надежность суммарной шкалы и подшкал. При интерактивном удалении позиций надежность результирующей шкалы вычисляется мгновенно без повторного обращения к файлу данных. В качестве результатов анализа выдаются: корреляционные матрицы и описательные статистики для позиций, альфа Кронбаха, стандартизованное альфа, средняя корреляция позиция-позиция, полная таблица дисперсионного анализа для шкалы, полный набор статистик, общих для всех позиций (включая коэффициенты множественной корреляции), split-half-надежность и корреляция между двумя половинками с поправкой на затухание.
Имеется большой выбор графиков (включая встроенные диаграммы рассеяния, гистограммы, линейные и другие графики) и набор интерактивных процедур что-если, помогающих при разработке шкал. Например, при добавлении некоторого количества вопросов в шкалу пользователь может вычислить ожидаемую надежность или же оценить количество вопросов, которые нужно внести в шкалу, чтобы добиться нужной надежности. Кроме того, можно внести поправку на затухание между текущей шкалой и другим измерением (при заданной надежности текущей шкалы).

Модуль системы STATISTICA содержит наиболее полную реализацию разработанных в последнее время методов эффективного построения и тестирования (метод деревьев классификации представляет собой определенный ("итерационный") способ предсказания класса, к которому принадлежит объект, по значениям предикторных переменных для этого объекта). Деревья классификации можно строить по категориальным или порядковым предикторам или смеси предикторов обоих типов посредством ветвлений по отдельным переменным или по их линейным комбинациям.
В модуле также реализованы: выбор между полным перебором вариантов ветвления (как в пакетах THAID и CART) и дискриминантным ветвлением; несмещенный выбор переменных ветвления (как в пакете QUEST); явное задание правил остановки (как в пакете FACT) или отсечение от листьев дерева к его корню (как в пакете CART); отсечение по доле ошибок классификации или по функции отклонения; обобщенные меры согласия хи-квадрат, G-квадрат и индекс Джини. Априорные вероятности принадлежности классам и цены ошибок классификации можно положить равными, оценить по данным или задать вручную.

Пользователь может также задавать кратность кросс-проверки во время построения дерева и для оценки ошибки, параметр SE-правила, минимальное число объектов в вершине отсечения, начальное число для датчика случайных чисел и параметр альфа для отбора переменных. Исследовать входные и выходные данные помогают встроенные графические средства.

Этот модуль содержит полную реализацию методов простого и многомерного анализа соответствий, в нем можно анализировать таблицы очень больших размеров. Программа воспринимает следующие типы файлов данных: файлы, содержащие категоризованные переменные, по которым строится матрица сопряженности (кросс-классификации); файлы данных, содержащие частотные таблицы (или какие-либо другие меры соответствия, связи, сходства, неупорядоченности и т. д.) и кодовые переменные, определяющие (перечисляющие) ячейки входной таблицы; файлы данных, содержащие частоты (или другие меры соответствия). Например, пользователь может непосредственно создать и проанализировать частотную таблицу. Кроме того, в случае многомерного анализа соответствий имеется возможность в качестве входных данных непосредственно задать матрицу Берта.
В процессе работы программа вычисляет различные таблицы, в том числе таблицу процентов по строкам, по столбцам и процентов от общего числа, ожидаемые значения, разности ожидаемых и наблюдаемых значений, стандартизованные отклонения и вклады в статистику хи-квадрат. Все эти статистики можно изобразить на трехмерных гистограммах и просмотреть с помощью специального метода динамического расслоения.
В модуле вычисляются обобщенные собственные значения и собственные векторы, и выдается стандартный набор диагностических величин, включающий сингулярные числа, собственные значения и долю инерции, приходящуюся на каждое измерение. Пользователь может либо сам выбрать число измерений, либо задать пороговое значение для максимального кумулятивного процента инерции.
Программа вычисляет стандартные координаты для точек-строк и точек-столбцов. Пользователь может выбрать между стандартизацией по профилям строк, по профилям столбцов, по профилям строк и столбцов или каноническую стандартизацию. Для каждой размерности и для каждой точки-строки и точки-столбца программа вычисляет величины инерции, качества и косинус**2. Дополнительно пользователь может вывести (в окно результатов) матрицы обобщенных сингулярных векторов. Как и любые данные из рабочего окна, эти матрицы доступны для обработки с помощью программ на языке STATISTICA Visual Basic, например, для использования каких-либо нестандартных методов вычисления координат.
Пользователь может вычислить координаты и соответствующие статистики (качество и косинус**2) для дополнительных точек (-столбцов или -строк) и сравнить результаты с исходными точками-строками и точками-столбцами. В многомерном анализе соответствий могут использоваться дополнительные точки. Помимо трехмерных гистограмм, которые могут быть вычислены для всех таблиц, пользователь может вывести на экран график собственных чисел, одно-, двух- и трехмерные диаграммы для точек-строк и точек-столбцов. Точки-строки и точки-столбцы могут отображаться одновременно на одной диаграмме вместе с любыми дополнительными точками (каждый тип точки использует свой цвет и уникальный маркер, так что различные точки будут легко различимы на диаграммах). Все точки имеют маркеры, и пользователь имеет возможность устанавливать размер маркера.

В модуле реализован полный набор методов (неметрического) многомерного шкалирования. Здесь можно анализировать матрицы сходства, различия и корреляций между переменными, а размерность пространства шкалирования может достигать 9. Начальная конфигурация может вычисляться программой (с помощью анализа главных компонент) или задаваться пользователем. Величина стресса и коэффициент отчуждения минимизируются с помощью специальной итерационной процедуры.
Пользователь имеет возможность наблюдать итерации и следить за изменениями этих значений. Окончательную конфигурацию можно просмотреть в таблице результатов, а также на двух- и трехмерных диаграммах рассеяния в пространстве шкал с отмеченными точками-объектами. В качестве выходных результатов выдаются: нестандартизованный стресс (F), коэффициент стресса Краскела S и коэффициент отчуждения. Уровень согласия может быть оценен с помощью диаграмм Шепарда (с величинами "d с крышкой" и "d со звездочкой"). Как и все результаты анализа в системе STATISTICA , окончательная конфигурация может быть сохранена в виде файла данных.

Модуль содержит полную реализацию методов пошагового дискриминантного анализа с помощью дискриминантных функций. STATISTICA также включает модуль Общие модели Дискриминантного анализа (GDA) для подгонки ANOVA/ANCOVA-подобных планов категориальных зависимых переменных или для выполнения различных типов анализов (например, лучший выбор предсказаний, профилирование апостериорных вероятностей).
Программа позволяет проводить анализ с пошаговым включением или исключением переменных или вводить в модель заданные пользователем блоки переменных. В дополнение к многочисленным графикам и статистикам, описывающим разделяющую (дискриминирующую) функцию, программа содержит также большой набор средств и статистик для классификации старых и новых наблюдений (для оценки качества модели). В качестве результатов выдаются: статистика лямбда Уилкса для каждой переменной, частная лямбда, статистика F для включения (или исключения), уровни значимости p, значения толерантности и квадрата коэффициента множественной корреляции. Программа выполняет полный канонический анализ и выдает все собственные значения (в непосредственном виде и кумулятивные), их уровни значимости p, коэффициенты дискриминантной (канонической) функции (в непосредственном и стандартизованном виде), коэффициенты структурной матрицы (нагрузки факторов), средние значения дискриминантной функции и дискриминантные веса для каждого объекта (их можно автоматически добавить в файл данных).
Встроенные средства графической поддержки включают: гистограммы канонических весов для каждой группы (и общие по всем группам), специальные диаграммы рассеяния для пар канонических переменных (на которых отмечено, к какой группе принадлежит каждое наблюдение), большой набор категоризованных (множественных) графиков, позволяющий исследовать распределение и взаимосвязи между зависимыми переменными для разных групп (в том числе: множественные графики типа диаграмм размаха, гистограммы, диаграммы рассеяния и нормальные вероятностные графики) и многое другое.
В модуле можно также вычислить стандартные функции классификации для каждой группы. Результаты классификации наблюдений можно вывести в терминах расстояний Махаланобиса, апостериорных вероятностей и собственно результатов классификации, а значения дискриминантной функции для отдельных наблюдений (канонические значения) можно просмотреть на обзорных пиктографиках и других многомерных диаграммах, доступных непосредственно из таблиц результатов. Все эти данные можно автоматически добавить в текущий файл данных для дальнейшего анализа. Можно вывести также итоговую матрицу классификации, где указано число и процент правильно классифицированных наблюдений. Имеются различные варианты задания априорных вероятностей принадлежности классам, а также условий отбора, позволяющих включать или исключать определенные наблюдения из процедуры классификации (например, чтобы затем проверить ее качество на новой выборке).
Общие модели дискриминантного анализа (GDA)
Модуль Общие модели дискриминантного анализа STATISTICA (GDA) является приложением и расширением Общих Линейных Моделей для классификации задач. Также как и модуль Дискриминантный Анализ , GDA позволяет выполнять обычные последовательные дискриминантные анализы. GDA представляет задачу дискриминантного анализа, как специальный случай общей линейной модели и, таким образом, предоставляет чрезвычайно полезные новые пользовательские аналитические технологии.
Также как и обычный дискриминантный анализ, GDA позволяет выбрать нужные категории зависимых переменных. В анализе группы элементов записаны в виде индикаторных переменных, и можно легко применять все методы GRM. В диалоге результатов GDA доступен широкий выбор остаточных статистик GRM и GLM.
GDA предоставляет разнообразные эффективные средства для добычи данных и прикладных исследований. GDA вычисляет все стандартные результаты дискриминантного анализа, включая коэффициенты дискриминантной функции, канонические результаты анализа (стандартизованные и необработанные коэффициенты, пошаговые тесты канонических корней и т. п.), классификационные статистики (включая, расстояние Махаланобиса, апостериорные вероятности, классификацию наблюдений в допустимых анализах, матрицы ошибочной классификации и т. п.). Для дополнительной информации об уникальных особенностях GDA
Аналитическое прогнозирование многомерных процессов.
Метод обобщенного параметра.
Цель работы: изучение практических приемов прогнозирования состояния многопараметрического объекта.
Краткие теоретические сведения:
Изменение состояния технических систем можно рассматривать как процесс, характеризуемый изменениями некоторого множества параметров. Положение вектора состояния в пространстве определяет степень работоспособности системы. Состояние системы характеризуется вектором в k-мерном пространстве, где координатами пространства служат k параметров системы , .
Прогнозирование состояния сводится к периодическому предварительному контролю параметров; определению в моменты t i T 1 контроля функции состояния
Q =Q[
 ] и расчете значений
функцииQ
состояния в области значений времениT 2
> T 1 .
] и расчете значений
функцииQ
состояния в области значений времениT 2
> T 1 .
При этом чем дальше будет расположен вектор состояния от гиперповерхности допустимых значений степени работоспособности Q * , тем выше работоспособность диагностируемой системы. Чем меньше разность * , тем ниже уровень работоспособности.
Использование методов аналитического прогнозирования предполагает регулярность изменения компонентов процесса во времени.
Идея метода обобщенного параметра заключается в том, что процесс, характеризуемый многими компонентами, описывается одномерной функцией, численные значения которой зависят от контролируемых компонентов процесса. Такая функция рассматривается как обобщенный параметр процесса. При этом может оказаться, что обобщенный параметр не имеет конкретного физического смысла, а является математическим выражением, построенным искусственно из контролируемых компонентов прогнозируемого процесса.
При обобщении параметров, характеризующих степень работоспособности технических систем, необходимо решение следующих задач:
Определения относительных значений первичных параметров;
Оценки значимости первичного параметра для оценки состояния объекта;
Построения математического выражения для обобщенного параметра.
Определение относительных значений первичных параметров необходимо в связи с тем, что состояния объекта может характеризоваться параметрами, имеющими различную размерность. Поэтому все контролируемые первичные параметры следует свести к единой системе исчисления, в которой они могут быть сравнимыми. Такой системой является система безразмерного (нормированного) относительного исчисления.
Реально для каждого параметра ,s = 1, 2, …, k можно выделить допустимое значение, * , при достижении которого объект теряет работоспособность, и оптимальное значение опт (зачастую оно равно номинальному значению н).
Пусть в
процессе эксплуатации объекта соблюдается
условие.
Если
![]() ,
достаточно ввести в местоновый параметр
,
достаточно ввести в местоновый параметр![]() и тогда длябудет соблюдаться требуемое условие.
и тогда длябудет соблюдаться требуемое условие.
Запишем безразмерный (нормированный) параметр в виде:

где
 ,
причем при
,
причем при
 , а при
, а при
 .
.
Таким образом, с помощью выражения (1) нормируется параметр , а безразмерная нормированная величинаизменяется с течением времени от 1 до 0. Отсюда по величинеможно судить о степени работоспособности объекта по данному параметру. Теоретически может быть, но это означает, что на практике объект неработоспособен.
Можно указать различные нормируемые выражения, которые оказываются удобными при решении частных задач, например:



и т. п., где
![]() – соответственно текущее, нулевое, мат.
ожиданиеS
– го параметра.
– соответственно текущее, нулевое, мат.
ожиданиеS
– го параметра.
Использование
нормирующих выражений позволяет получить
совокупность безразмерных величин,
которые характеризуют состояние объекта.
Однако количественно одинаковое
изменение этих величин не является
равнозначным по степени влияния на
изменение работоспособности объекта,
поэтому необходимо дифференцировать
первичные параметры. Этот процесс
осуществляется с помощью весовых
коэффициентов, величины которых
характеризуют важность соответствующих
параметров для физической сущности
задачи. Пусть в таком случае параметрам
объекта
![]() соответствуют весовые коэффициенты
соответствуют весовые коэффициенты![]() ,
удовлетворяющие тем или иным заданным
критериям, причем
,
удовлетворяющие тем или иным заданным
критериям, причем ![]() .
.
Степень работоспособности объекта по множеству контролируемых параметров можно оценить с помощью обобщающего выражения

Где - обобщенный параметр объекта.
Выражение (2) представляет собой линейное среднее. Из определения обобщенного параметра следует, что чем больше величина и, тем больше вкладS – го слагаемого (параметра) в .
Обобщенный параметр можно определить с помощью выражения вида
 ,
(3)
,
(3)
которое представляет
собой нелинейного среднее. Для такой
модели также соблюдается условие: чем
больше
и,
тем больший вклад вносит слагаемое в величину.
в величину.
На практике находят применение и другие формы записи нелинейного среднего, например:
 ,
(4)
,
(4)
 ,
(5)
,
(5)
где подбирает так, чтобы (5) давая лучшее приближения к результатам, полученным экспериментальным путем.
При рассмотрении выражений для обобщенного параметра считалось, что не меняет знака, т. е. всегда . Если же необходимо учитывать знак, выражение (2) преобразуется к виду
 ,
(6)
,
(6)
Таким образом, использование обобщенного параметра позволяет свести задачу прогнозирования состояния многопараметрического объекта к прогнозированию одномерной временной функции.
Пример. Испытания объекта в течении 250 часов, у которого контролировалось 6 параметров, дали результаты, приведенные в таблице1.
Таблица1
|
I н, ном = 9,5 |
V g1 . ном = 120 |
I а, ном = 2,0 |
I g3 , ном = 70 | |||
После нормирования значений параметров с помощью выражения (1) таблица принимает вид (таблица2)
Таблица2
© 2005 г. А. И. Саичев*, С. Г. Уткин*
ПЕРЕХОД МНОГОМЕРНЫХ СКАЧКООБРАЗНЫХ ПРОЦЕССОВ ОТ АНОМАЛЬНОЙ К ЛИНЕЙНОЙ ДИФФУЗИИ
Рассматриваются многомерные процессы "квазианомальных" случайных блужданий, имеющие линейно-диффузионную асимптотику на больших временах и подчиняющиеся аномально-диффузионным закономерностям на промежуточных (также достаточно больших относительно микроскопических масштабов) временах. Демонстрируется переход скачкообразного процесса от аномальной к линейной диффузии. С помощью численного счета подтверждается справедливость аналитических расчетов для двумерного и трехмерного случаев. , .....
Ключевые слова: аномальная субдиффузия, аномальная супердиффузия, уравнения в частных дробных производных, промежутоная асимптотика, квазианомальные случайные блуждания.
1. ВВЕДЕНИЕ
Главным признаком аномальной диффузии служит нелинейный рост среднего квадрата случайного процесса со временем: >г: V» „
характерный, например, для таких физических явлений, как турбулентная диффузия , хаотическая динамика гамильтоновых систем , , перенос заряда в аморфных полупроводниках и др. Динамика подобных явлений адекватно моделируется скачкообразными случайными процессами с теми или иными распределениями / (г) интервалов между скачками и распределениями w(x) величины скачков.
Известно также, что аномальная диффузия возникает из-за нарушения центральной предельной теоремы (ЦПТ) или закона больших чисел (ЗБЧ) (см., например, ). В свою очередь, неприменимость ЗБЧ обусловлена бесконечностью первых моментов времени ожидания скачков, а нарушение ЦПТ связано с бесконечностью вторых моментов скачков. Эти обстоятельства служат объектом критики теории аномальной диффузии со стороны физиков, справедливо замечающих, что для большинства физических явлений указанные моменты ограничены.
"Нижегородский государственный университет, Нижний Новгород, Россия. E-mail: [email protected]; [email protected]
Цена 18 ^уб. Переплет 1 р.
456 А. И. САИЧЕВ, С. Г. УТКИН;
Целью данной работы является демонстрация того факта, что аномальная субдиффузия может возникать и в "классическом случае", когда ЗБЧ и ЦПТ справедливы. А именно, наряду с детально исследованными "чисто" аномальными диффузионными процессами существуют и "квазианомальные" случайные процессы, подчиняющиеся законам линейной диффузии на очень больших временах и пространственных масштабах, а на "промежуточных" временах демонстрирующие универсальные аномально-диффузионные асимптотики. Данная работа посвящена анализу именно таких квазианомальных случайных процессов в пространствах разной размерности. Обнаружено, в частности, что, в отличие от классической многомерной диффузии, случайные координаты аномально-диффузионного скачкообразного процесса статистически зависимы даже при независимых компонентах векторов случайных скачков.
2. СЛУЧАЙНЫЕ БЛУЖДАНИЯ
Рассмотрим типичный процесс случайных блужданий, подчиняющийся простейшему стохастическому уравнению чч-.
*-----. < к 1
Без ограничения общности предположим, что случайные интервалы ожидания скачков т~к = tk - ifc-i и сами случайные скачки hk взаимно независимы, а также имеют одинаковые распределения /(т) и w(x), соответственно. Очевидно, что
где N(t) - число скачков к моменту t. Это функция, обратная времени n-го скачка Т(п):
t = T(n) = ] " "
Используя очевидное соотношение эквивалентности для этих функций ~ !! N(t)^n T{n) и разбиение единицы - м. .„ >».. л ■ >. 1= ^IIn(z) = ^, z>0, "У ■ где x(z) - функция ступеньки, выведем уравнение для характеристической функции рассматриваемого процесса X (f): ©(«; t) = (¿»ХМ) = £ /ехр (ш £ hk) V п=0 ^ ^ fc=1 " " Цена 18 дуб. Переплет Í р. ■го) аномальная субдиф-и ЦПТ справедливы. А ми диффузионными про-л, подчиняющиеся зако-анственных масштабах, ьные аномально-диффу-но таких квазианомаль-1. Обнаружено, в част-I, случайные координа-гически зависимы даже шяющиися простеише- 1лы ожидания скачков а также имеют одина-) 1ени п-го скачка Т(п): г > О, ^ " ической функции рас- ПЕРЕХОД МНОГОМЕРНЫХ СКАЧКООБРАЗНЫХ ПРОЦЕССОВ. .. Применим к обеим частям равенства преобразование Лапласа и просуммируем полученную геометрическую прогрессию: Найденное выражение для лаплас-образа 0(u; s) характеристической функции представляет собой многомерный аналог уравнения Монтролла-Вейсса . Здесь f(s) -лаплас-образ распределения интервалов между скачками, a w(u) - характеристическая функция скачков. Из последнего равенства видно, что Q(u; s) подчиняется уравнению 0(u;s) - w(u)Q(u;s) = ........... ÎM (2-2) Применив к нему обратные преобразования Фурье и Лапласа, легко получить (в зависимости от вида распределений /(г) и w(x)) как классическое уравнение Колмогоро-ва-Феллера, так и кинетические уравнения аномальной диффузии. 3. АСИМПТОТИЧЕСКИЕ УРАВНЕНИЯ ДЛЯ ПЛОТНОСТИ ВЕРОЯТНОСТЕЙ БЛУЖДАНИЙ X(t) Как уже было отмечено выше, вид уравнения для плотности вероятностей W(x; t) зависит от вида распределений /(г) и tu (ж), а точнее - от их лаплас-образа f(s) и характеристической функции w(u). Далее будут получены асимптотические уравнения для W(x; t), справедливые на различных временных масштабах, в случае распределения/(г) с лаплас-образом V "I + sp " > где S - малый параметр. Все моменты /(г) ограничены, что делает его физически более корректным, нежели родственное ему дробно-экспоненциальное распределение - (отвечающее значению 6 = 0), являющееся одним из ключевых в теории аномальной диффузии. Рассмотрим случай, когда параметр 6 мал настолько, что временной интервал между 1 и 1/(5 достаточно велик. Тогда процесс X(t) проходит последовательно три стадии. Вначале, на временах t 1, поведение процесса зависит от тонкой структуры распределений / (г) ию(х) ияе отражает универсальных законов диффузии. Далее, на временах между 1 и 1/6, за счет медленно спадающих степенных хвостов распределения /(т) процесс подчиняется аномально-диффузионным законам. Затем, при t 3> 1/6, процесс подчиняется нормальному линейно-диффузионному закону благодаря экспоненциально убывающим при т 1/6 хвостам распределения /(г). Подставим f(s) (3.1) в уравнение (2.2) и обсудим его асимптотику при s 1, что соответствует вероятностным свойствам скачкообразного процесса на больших временах. Применительно к лаплас-образу распределения /(т) выделим случай s Цена 18 ^уб. Переплет 1 р. и (2.2) примет вид А. И. САИЧЕВ, С. Г. УТКИН в ©(«;«) + - ш(«)]в(«; 5) = 1, а во втором/(в) ~ 1 - (1 + 8$) и, соответственно, «"§(«; э) + (1 + - й(«)]в(и; «) = в"-1. Применяя к полученным равенствам обратное преобразование Фурье и Лапласа, придем к уравнению Колмогорова-Феллера > + [цг{х.^ _ * Ц*)] = < оо, или к обобщенному уравнению Колмогорова-Феллера А+б0)т*м) - ж{х-л)*ю(,х)} = 1«*« характерной, например, для многомерного нормального распределения с независимыми координатами и одинаковой дисперсией а2 по всем осям. Тогда из приведенных выше уравнений вытекают соответственно уравнения линейной и аномальной диффузии для разных временных асимптотик: е- л ".(< "■ т? 2ч* "" ч"#""" " г(1 -0) Решение первого из них хорошо известно: хШх), !«*<-. (3.3) * " И" (х О- (1 + 1 + - где п - размерность пространства случайного процесса. Решение второго уравнения приведено в следующем разделе. Для того ч в п-мерном щ компонентам ного аргуме! /3-устойчиво Многомерна таг-Леффле Таким обрг диффузии }









Обзор Samsung Galaxy A7 (2017): не боится воды и экономии Стоит ли покупать samsung a7
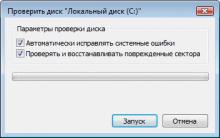
Делаем бэкап прошивки на андроиде
Как настроить файл подкачки?
Установка режима совместимости в Windows
Резервное копирование и восстановление драйверов Windows