→ Оптимизация запросов MySQL
MySQL располагает большим набором функций для различных сортировок (ORDER BY ), группировок (GROUP BY ), объединений (LEFT JOIN или RIGHT JOIN ) и так далее. Все они безусловно удобны, но в условиях одноразовых запросов. К примеру, если лично Вам требуется что-то откопать в базе используя кучу таблиц и связок, то кроме вышеперечисленных функций можно и даже нужно применять условный операторы IF . Главная ошибка начинающих программистов это стремление применить такие запросы в рабочем коде сайта. В данном случае сложный запрос безусловно красив, но вреден. Все дело в том, что любые операторы сортировок, группировок, объединений или вложенных запросов, не могут выполняться в оперативной памяти, и используют жесткий диск для создания временных таблиц. А хард, как известно - самое узкое место сервера.
Правила оптимизации mysql запросов
1. Избегайте вложенных запросов
Это самая серьезная ошибка. Родительский процесс всегда будет ждать завершения дочернего и в это время держать коннект к базе, использовать диск и нагружать iowait. Два параллельных запроса в базу и выполнения нужных фильтраций в серверном интерпретаторе (Perl , PHP и т. д.), выполнятся на порядок быстрее чем вложенный.
Примеры на perl , как делать не следует:
My $sth = $dbh->prepare("SELECT elementID,elementNAME,groupID FROM tbl WHERE groupID IN(2,3,7)"); $sth->execute(); while (my @row = $sth->fetchrow_array()) { my $groupNAME = $dbh->selectrow_array("SELECT groupNAME FROM groups WHERE groupID = $row"); ### Допустим нужно собрать названия групп ### и добавить их в конец массива с данными push @row => $groupNAME; ### Делаем еще что-нибудь... }
или не в коем случае вот так:
My $sth = $dbh->prepare("SELECT elementID,elementNAME,groupID FROM tbl WHERE groupID IN(SELECT groupID FROM groups WHERE groupNAME = "Первая" OR groupNAME = "Вторая" OR groupNAME = "Седьмая")");
Если есть необходимость подобных действий, во всех случаях лучше использовать хеш, массив или любой другой путь для фильтрации.
Пример на perl, как делаю обычно я:
My %groups; my $sth = $dbh->prepare("SELECT groupID,groupNAME FROM groups WHERE groupID IN(2,3,7)"); $sth->execute(); while (my @row = $sth->fetchrow_array()) { $groups{$row} = $row; } ### А теперь выполням основную выборку без вложенного запроса my $sth2 = $dbh->prepare("SELECT elementID,elementNAME,groupID FROM tbl WHERE groupID IN(2,3,7)"); $sth2->execute(); while (my @row = $sth2->fetchrow_array()) { push @row => $groups{$row}; ### Делаем еще что-нибудь... }
2. Не сортируйте, не группируйте и не фильтруйте в базе
По возможности не применяйте в своих запросах операторы ORDER BY, GROUP BY, JOIN. Все они используют временные таблицы. Если сортировка или группировка необходима только для вывода элементов, например по алфавиту, лучше выполнить эти действия в переменных интерпретатора.
Примеры на perl, как сортировать не следует:
My $sth = $dbh->prepare("SELECT elementID,elementNAME FROM tbl WHERE groupID IN(2,3,7) ORDER BY elementNAME"); $sth->execute(); while (my @row = $sth->fetchrow_array()) { print qq{$row => $row}; }
Пример на perl, как сортирую обычно я:
My $list = $dbh->selectall_arrayref("SELECT elementID,elementNAME FROM tbl WHERE groupID IN(2,3,7)"); foreach (sort { $a-> cmp $b-> } @$list){ print qq{$_-> => $_->}; }
Так намного быстрее. Особенно заметна разница если данных много. В случае, если нужно отсортировать в perl по нескольким полям, можно применить сортировку Шварца . Если требуется произвольная сортировка ORDER BY RAND() - используйте сортировку random в perl .
3. Используйте индексы
Если от сортировки в базе можно отказаться в некоторых случаях, то от WHERE навряд ли удастся. Поэтому, для полей, по которым будет идти сравнение, необходимо устанавливать индексы. Делаются они просто.
Таким запросом:
ALTER TABLE `any_db`.`any_tbl` ADD INDEX `text_index`(`text_fld`(255));
Где 255 - длина ключа. Для некоторых типов данных он не требуется. Подробности в документации к MySQL.
От автора: один мой знакомый решил оптимизировать свой автомобиль. Сначала одно колесо снял, потому крышу спилил, затем мотор… В общем, сейчас он пешком ходит. Это все последствия неправильного подхода! Поэтому, чтобы ваша СУБД продолжала «ездить», оптимизация MySQL должна проходить правильно.
Когда оптимизировать и зачем?
Лишний раз лезть в настройки сервера и изменять значения параметров (особенно, если не знаете, чем это может закончиться) не стоит. Если рассматривать данную тему с «колокольни» улучшения производительности веб-ресурсов, то она настолько обширная, что ей нужно посвящать целое научное издание в 7 томах.
Но такого писательского терпения у меня явно нет, да и у вас читательского тоже. Мы поступим проще, и постараемся лишь слегка углубиться в чащи оптимизации MySQL сервера и его составляющих. С помощью оптимальной установки всех параметров СУБД можно достигнуть нескольких целей:
Увеличить скорость выполнения запросов.
Повысить общую производительность сервера.
Уменьшить время ожидания загрузки страниц ресурса.
Снизить потребление серверных мощностей хостинга.
Снизить объем занимаемого дискового пространства.
Постараемся всю тематику оптимизации разбить на несколько пунктов, чтоб было более-менее понятно, от чего «котелок» закипает .
Зачем настраивать сервер
В MySQL оптимизацию производительности следует начинать с сервера. Прежде всего, следует ускорить его работу и уменьшить время обработки запросов. Универсальным средством для достижения всех перечисленных целей является включения кэширования. Не знаете, «what is it»? Сейчас все поясню.
Если на вашем экземпляре сервера включено кэширование, то система MySQL автоматически «запоминает» введенный пользователем запрос. И в следующий раз при его повторении данный результат запроса (на выборку) будет не обработан, а взят из памяти системы. Получается, что таким образом сервер «экономит» время на выдачу ответа, и вследствие чего скорость реагирования сайта повышается. В том числе это касается и общей скорости загрузки.
В MySQL оптимизация запросов применима к тем движкам и CMS, которые работают на основе данной СУБД и PHP. При этом код, написанный на языке программирования, для генерации динамической веб-страницы запрашивает некоторые ее структурные части и содержимое (записи, архивы и другие таксономии) из БД.
Благодаря включенному кэшированию в MySQL выполнение запросов к серверу СУБД происходит намного быстрее. За счет чего и повышается скорость загрузки всего ресурса в целом. А это положительно отражается и на пользовательском опыте, и на позиции сайта в выдаче.
Включаем и настраиваем кэширование
Но давайте вернемся от «скучной» теории к интересной практике. Дальнейшую оптимизацию базы MySQL продолжим с проверки состояния кэширования на вашем сервере БД. Для этого с помощью специального запроса мы выведем значения всех системных переменных:
Совсем другое дело.
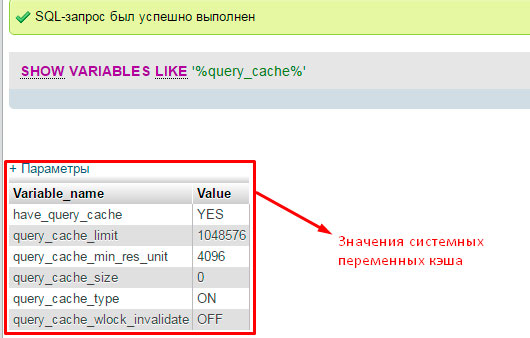
Сделаем маленький обзор полученных значений, которые пригодятся нам для оптимизации баз данных MySQL:
have_query_cache – значение показывает «ВКЛ» кэширование запросов или нет.
query_cache_type – отображает активный тип кэша. Нам нужно значение «ON». Это говорит о том, что кэширование включено для всех видов выборки (команда SELECT). Кроме тех, в которых используется параметр SQL_NO_CACHE (запрещает сохранение информации об этом запросе).
У нас все настройки заданы правильно.
Отмеряем кэш под индексы и ключи
Теперь нужно проверить, сколько отведено оперативной памяти под индексы и ключи. Рекомендуется устанавливать этот важный для оптимизации БД MySQL параметр на 20-30% от объема оперативки, доступной для сервера. Например, если под экземпляр СУБД выделено 4 «гектара», то смело ставьте 32 «метра». Но все зависит от особенностей определенной базы и ее структуры (типов) таблиц.
Для установки значения параметра нужно отредактировать содержимое конфигурационного файла my.ini, который в Денвере находится по следующему пути: F:\Webserver\usr\local\mysql-5.5

Файл открываем с помощью Блокнота. Затем находим в нем параметр key_buffer_size и устанавливаем оптимальный для вашей системы ПК (в зависимости от «гектаров» оперативки) размер. После этого нужно перезапустить сервер БД.

В СУБД используется несколько дополнительных подсистем (нижнего уровня), и все основные их настройки также задаются в данном файле конфигурации. Поэтому, если нужно провести в MySQL InnoDB оптимизацию, то добро пожаловать сюда. Более подробно эту тему мы изучим в одном из наших следующих материалов.
Измеряем уровень индексов
Использование индексов в таблицах значительно повышает скорость обработки и формирования ответа СУБД на введенный запрос. MySQL постоянно «измеряет» уровень применения индексов и ключей в каждой БД. Для получения данного значения используйте запрос:
SHOW STATUS LIKE "handler_read%"
SHOW STATUS LIKE "handler_read%" |

В полученном результате нас интересует значение в строке Handler_read_key. Если указанное там число маленькое, то это говорит о том, что индексы почти не используются в данной базе. А это плохо (как у нас ).
- Разместил Николай Коротков
- Дата: 8 декабря 2012 в 14:04
Для чего все это нужно? На что влияет? Как воплотить в реальность? На все эти вопросы я постараюсь дать четкий ответ в этом посте!
А теперь небольшая предыстория. В общем, недавно получил письмо на свой e-mail адрес, следующего содержания:
В течение последних 3 дней средний уровень нагрузки, создаваемый Вашим аккаунтом ******* , составил 119% от допустимого уровня Вашего тарифного плана. Мы рекомендуем Вам перейти на тарифы VPS. Обращаем Ваше внимание, что в случае регулярного превышения лимитов, мы оставляем за собой право заблокировать Ваш аккаунт согласно пункту Договора...
Оба на, приплыли — подумал я в тот момент! Согласитесь, не очень приятно получать такие письма. А так как с подобного рода проблемой я столкнулся впервые, представляете, в каком я был недоумении? Моему возмущению не было предела! Какой нафиг VPS? Я можно сказать только обжился на одном тарифе, а мне тут предлагают перейти на виртуальный хостинг, который в три раза дороже. Ну нет уж ребята, — думаю я, — еще рановато.
Пишу в обратку письмо моему хостеру, с просьбой пояснить мне, с какого это перепуга у меня зашкаливает нагрузка? Ведь моему блогу всего-то два с небольшим месяца от роду. Да и посещаемость не велика. В общем, пишу, что категорически против переходить на VPS, считаю, что это не целесообразно на столь раннем этапе развития ресурса и прошу указать мне на мои ошибки, что с ними делать и как в дальнейшем их контролировать!
В ответ получаю следующее:
Уважаемый абонент, мы вас не собираемся отключать именно сейчас, это банальное предупреждение, но мол надо с этим, что-то делать. Проблема превышения нагрузки не зависит напрямую от посещаемости, а в большей степени зависит от не правильной оптимизации вашего ресурса. Для отслеживания нагрузки мы вам вывели в панели управления счетчик, который обновляется каждые 10 минут:

Ну спасибо за разъяснения, — думаю про себя. Пойду изучать проблему. Набрав в интернете запрос «как снизить нагрузку на хостинг» понял, что я не один такой, а на самом деле проблема довольно актуальная. И рано или поздно коснется многих. Ознакомившись более детально с проблемой, понял, что у меня есть два выхода из данной ситуации:
- Обратиться за помощью к профессионалам (фрилансерам), заплатив им определенную сумму денег, что всегда успеется.
- Постараться устранить проблему самому.
Так вот, я выбрал второй вариант и скажу вам честно, пока что ни на грамм не пожалел. Мне удалось снизить нагрузку на хостинг в два-три раза. Вот посмотрите сами:

Разница, на лицо! Сейчас я вам покажу и расскажу, что я для этого сделал:
— оптимизировал базу данных mysql, что существенно отразилось на снижении нагрузки на хостинг и ускорении wordpress;
— избавился от порядка 8 ненужных плагинов.
— ускорил wordpress, отредактировав несколько файлов темы своего блога.
Так как материал довольно таки объемный, я решил разбить его на три части. Из этой статьи вы узнаете, как снизить нагрузку на хостинг за счет оптимизации базы данных. В следующей статье я вам расскажу, . И последняя статья будет на тему . Когда я все это проделал со своим ресурсом, я был в шоке над тем, как мой блог стал грузиться! По сравнению с тем, что было — он стал летать.
В общем, материал, который вы почерпнете из этих трех постов, будет ну просто обалденным. Не пропустите, !
Оптимизация базы данных
Прежде чем вы начнете производить различные действия с базой данных, обязательно делайте резервную копию . Чтобы в случае возникновения проблем можно было все быстренько восстановить. База данных содержит всю историю вашего ресурса, в ней хранятся все записи, присутствующие на вашем блоге! А вообще, советую вам взять за правило сохранять базу данных каждый день! Это у вас займет буквально 1 минуту, но зато вы будете всегда спать спокойно. Сами понимаете может случится всякое.
1. Делаем резервную копию базы данных
Для удобства соединения с сервером и обработки данных я пользуюсь . Очень классная штука, как-нибудь напишу об этом клиенте отдельный пост, . В общем, вам нужно перейти на свой сервер и найти в нем вкладку «Базы данных» или «Базы данных MySQL», что-то в этом роде. На каждом сервере база данных есть, при переходе сервер может запросить пароль. Он у вас должен быть. При покупке хостинга пароль предоставляется.
В итоге вы должны оказаться вот на такой странице, phpMyAdmin:

Заходите в базу данных, кликнув по ее названию. Перед вами откроется таблица базы данных (кликните для увеличения):

Нажимаете «Экспорт» и «ОК». Сохраняете на своем ПК. Все, база данных сохранена, теперь можем приступать к ее оптимизации. Обратите внимание, если на вашем хостинге присутствует поле «Сохранить как файл» не забудьте напротив него поставить галочку! А также запомните, сколько весит в данный момент ваша база данных, а потом посмотрите сколько она будет весить после оптимизации.
У меня она весила до оптимизации 26 Mb — это УЖАС, а что сейчас? А сейчас она весит всего 2 Mb! Представляете, сколько всякого ненужного хлама она содержала в себе? Представляете, какую нагрузку она создавала на сервере? После оптимизации базы данных, мой блог стал летать, как реактивный самолет! В общем, после того как вы проделаете все ниже описанные действия, вы почувствуете существенную разницу!
2. Отключаем ревизии постов и устанавливаем минимальный срок хранения удаленных файлов в корзине
Что такое ревизия постов? Когда вы пишите пост в блог, wordpress автоматически, через определенный промежуток времени, сохраняет резервную копию каждого поста в базе данных, в общем, делает авто сохранение. А теперь представьте когда вы напишите 50 постов на блоге? Сколько копий постов у вас будет сохранено? Это ЖЕСТЬ! Пока вы пишите пост, у вас уже как минимум проходит 10 авто сохранений!
Плюс ко всему этому, если вы удаляете файлы, они у вас скапливаются в корзине, что также нагружает базу данных. Конечно, хорошо если вы сразу удалите файл и из корзины, но частенько случается, что многие про это забываю, а некоторые просто забивают! А это ой как не хорошо... База все растет, нагрузка на сервер все больше и больше, блог грузится все медленнее и медленнее... Вы задумывались, к каким последствиям это может привести?
Вот основная часть последствий, но далеко не всех: снижение , частые отказы, ухудшение , понижение позиций в выдаче поисковиков... А дальше, автор в подает в отчаяние от не оправданных ожиданий. Желание вести блог со временем пропадает и все! КРАХ!
Все это я к чему говорю? За базой данных постоянно нужно следить и содержать ее в надлежащем состоянии. Поймите, база данных — это как сердце блога. При постоянной нагрузке на сердце не нужным хламом, со временем оно не выдержит и ОСТАНОВИТСЯ! Я думаю, вы меня поняли? Поэтому хватит ужастиков и переходим к оптимизации базы данных.
Итак, открываем файл wp-config.php, он находится в корне вашего блога, т.е. ваш хостинг/httpdocs или public_html (в зависимости от хостинга)/wp-config.php. И вставляем в него две строчки:
| 1 2 | define ("WP_POST_REVISIONS" , false) ; define ("EMPTY_TRASH_DAYS" , 1 ) ; |
Строка №1 отключает ревизию постов, строка №2 означает, сколько дней будут храниться удаленные файлы в вашей корзине. Как видите, я поставил «1», можно конечно поставить и «0», но если вдруг по неосторожности у вас дрогнет рука и вы нажмете на ссылку «удалить», все — КАПЕЦ!

А после просиживания за компом 5-8 часов, поверьте мне, это возможно! Так что я предпочитаю оставить циферку «1». Конечно, после удаления файла лучше сразу же почистить корзину вручную, но если даже вы забудете это сделать, спустя сутки файл из корзины автоматически удалится! Вот как это выглядит у меня:

3. Удаляем ревизии постов
Если в предыдущем пункте мы отключили ревизию постов, то в этом пункте нам нужно удалить все ревизии постов, скопившиеся за все время ведения блога. Если вы этого не разу не делали, то у вас сохранилось их невероятно большое количество! Давайте это сделаем. Копируем вот эту строку:
Переходим снова в базу данных MySQL, как описано в первом пункте. Заходим во вкладку SQL, вставляем в поле скопированную строчку и нажимаем «ОК»:

База данных спросит:

Отвечаем «ОК» и смотрим, сколько не нужных ревизий постов содержала в себе ваша база данных, и сколько времени уходило на то, чтобы запрос обработать. А каждая частичка времени дает свою нагрузку:

Я делал чистку 3 дня назад, поэтому у меня она еще не обросла ревизиями. Когда я первый раз почистил базу, у меня было удалено аж 1800 с чем-то строк! Представляете, сколько копий ненужных постов в ней хранилось? Идем дальше.
4. Оптимизируем записи в wp-post
Папка wp-post содержит все записи блога. Точно так же как и в предыдущем пункте, копируем строку:
| OPTIMIZE TABLE wp_posts; |
И вставляем в поле SQL запроса. Нажимаем «ОК», смотрим:

Все, запрос выполнен!
5. Чистим wp-postmeta
Что именно будем чистить? Папка wp-postmeta содержит в себе:
— время последнего редактирования какого-либо из постов. Значения никакого не имеет, а нагрузку на сервер, какую никакую, а дает;
— содержание предыдущего (человека понятного урла). Если вы когда-нибудь меняли постоянную ссылку в любом посте. То при смене ее, она не удаляется, а оседает в папке wp-postmeta и нагружает вашу базу.
Делаем все тоже самое, копируем вот этот код:
Вставляем его в поле запроса SQL, и жмем «ОК». Смотрим на результат:

6. Удаляем спам-комментарии
Делается аналогично, копируем код:
Вставляем в поле SQL запроса, жмем «ОК», смотрим результат:

Как вы видите «0». После выполнения этого запроса, вы забудете про спам комментарии!
7. Удаляем пингбеки
Пингбеки — это уведомления о том, что на ваш пост или страницу кто-то ссылается. Нам это не нужно, лишняя нагрузка! Удаляем!
8. Отключаем пингбеки
Из прошлого пункта мы выяснили, что пингбеки не несут никакой пользы для нашего ресурса, а только его засоряют. Поэтому давайте их и вовсе отключим. Копируем этот код:
| UPDATE wp_posts p SET p. ping_status = "closed" |
Ну как вам такая чистка? Понравилась? А теперь посмотрите, сколько стала весить ваша база данных после ее оптимизации? Заметно уменьшился размер? А я вам говорил! Посмотрите, как стал грузиться ваш блог! Он должен летать! Но и это еще не все на сегодня. Сейчас мы рассмотрим еще один последний пункт, который также существенно улучшит оптимизацию.
9. Устанавливаем плагин Optimize DB
Об этом плагине я уже вкратце упоминал . Ну давайте более подробно рассмотрим, как им пользоваться. Данный плагин, как вы уже догадались, способствует оптимизации базы данных! Скачайте архив с плагином себе на ПК, вот и активируйте его:


Все, ваша база данных оптимизирована дополнительно при помощи плагина:

После оптимизации деактивируйте плагин, чтобы он не нес дополнительной нагрузки на ваш ресурс. И вообще, советую вам производить все выше описанные действия с периодичностью раз в месяц можно даже чаще. И тогда ваш блог будет грузиться молниеносно и нагрузка на сервер будет минимальной.
А в следующей части поста, я вам покажу, как заменить часть не ненужных плагинов кодами. Обязательно , чтобы ничего не пропустить. Это будет мощный пост, после которого ваш сервер будет легок как пушинка!
А на этом я с вами буду прощаться. На сегодня у меня все, желаю всем успехов, и помните это колоссальное снижении нагрузки на ваш ресурс. Всем пока и до скорых встреч.
И на последок порция приколов:
Ну как вам статья? Я уверен, что вы останетесь довольны после ее прочтения и проделанных рекомендаций со своим ресурсом! Жду ваших комментариев!
Понравилась статья? Поделись с друзьями!

Каждому комментатору книга в подарок!
Книга включает в себя подробное описание самых эффективных методов продвижения вашего ресурса!
60 комментариев
- Александр
8 декабря 2012 15:18
А я знаю почему у Тебя нагрузка так выросла. Просто я тут у Тебя прижился, и постоянно что то изучаю. А что делать если инфа здесь классная. А если серьезно, то все вышеперечисленные советы рекомендую сделать всем блоговодам в первую очередь. Я это давно сделал, поэтому сплю спокойно. И еще, плагин Optimize DB, это вообще обязательный атрибут любого Блога. Спасибо Коля, как всегда, все полезно и актуально. А вот следующий пост вообще жду с нетерпением. Так что давай, пиши
-
9 декабря 2012 16:19
Я в базе данных ковыряться побаиваюсь, но после установки и чистки плагином WP-Cleanup она у меня уменьшилась с почти 50 до 7Mb. Блог действительно стал грузиться намного быстрее.
-
9 декабря 2012 20:39
Строго говоря, спрашивает при операциях с базой данных не сама БД (СУБД вообще все действия одинаковы, ничего не спрашивает), а клиент, phpMySql.
Касательно пингбэков, «Из прошлого пункта мы выяснили, что пингбеки не несут никакой пользы для нашего ресурса, а только его засоряют.» — строго говоря, ничего не выяснили.
Вы просто сказали, не аргументируя, что они не нужны, вот и всё. На самом деле, польза от них вполне может быть, просто употреблять этот инструмент нужно по назначению. Например, ключевое слово «семантическая сеть» вам говорит что-нибудь?
- 10 декабря 2012 08:36
- Юрий
16 декабря 2012 23:49
Привет, дружище!
Твой пост и в самом деле классный. В Интернете столько много бредни написано, что информацию приходится искать по крупицам. А здесь я зашел, и на тебе, все доходчиво и понятно. У меня как раз началась проблема с нагрузкой на сервер. Еще советую установить плагин WP Super Cache. Только его нужно грамотно настроить. Классный плагин! Может у тебя в остальных постах о нем что-то и сказано, но я еще не читал. Спешу перейти ко второй части оптимизации. Удачи тебе и твоему блогу
- 25 декабря 2012 11:40
-
28 января 2013 11:24
Добрый день! Очень интересно, а как быть мне с блогом на Blogger? Все плагины для WP не годятся для Блогспот, нужно искать методы оптимизации самостоятельно в инете.
С уважением, Вадим.
- Антон
2 апреля 2013 20:34
Спасибо, пост действительно добротный. У меня, кстати, после проделывания пункта №3 — «Удалено 4145 строк. (Запрос занял 7.0269 сек.)»
-
14 июля 2013 19:04
Интересно, а как-то можно почистить базу от старых плагинов? наверняка там от них тоже следы какие-то остались?
-
14 июля 2013 19:06
Вдогонку: а еще очень похоже на ваш текст вот тут dayafternight.ru/wordpress/baza-dannih-mysql-optimizacia
-
12 сентября 2013 12:57
Спасибо Николай, нужная вещь.
Все доступно и понятно написано.
А статья про коды уже вышла?
-
12 сентября 2013 13:05
Николай забыла спросить, подскажите пожалуйста. Когда делала оптимизацию обнаружила у себя в PhpMyadmin новую базу данных information_schema
Подскажите откуда она могла появиться?
в последнее время только код яндекс-метрики вставляла.
Наталья Гегер
Не обращайте на это внимание... На большинстве современных серверов она есть! Связано это с выходом MySQL версии 5.0 и выше...
INFORMATION_SCHEMA — это виртуальная база, которая формируется во время запуска сервера и содержит в себе метаданные всех баз данных, т.е. информацию о структуре баз данных. Доступна она только для чтения.
-
27 октября 2013 01:06
ох, почистил базу по вашему методу + от себя ручками, результат на лицо. Раньше база весила 20мб, сейчас 5мб
-
29 октября 2013 23:34
Спасибо огромное за статью. Сегодня тоже получил втык от хостера. В результате действий, база из 25Мб стала 5,2. Есть 2 вопроса, эти все манипуляции надо делать периодически? И второй вопрос, установил плагин, нажимаю оптимизировать, в результате напротив каждой строки пишется,
note: Table does not support optimize, doing recreate + analyze instead
Не похоже, что всё хорошо?!
Пожалуйста! Да, я делаю все эти манипуляции, примерно один раз в месяц. А вот насчет плагина пока не могу ничего сказать, видимо вы что-то сделали не правильно. Попробуйте поискать информацию в интернет по этому поводу. Но есть и приятные события. Вы оставили на моем блоге 2100-й комментарий и за это вам полагается приз в размере 100 рублей:

Присылайте номер своего wmr-кошелька и я перечислю вам деньги.
-
30 октября 2013 13:27
Спасибо, приз получен. Как я оказался на Вашем сайте?! Вчера очередной раз сайт перестал работать, а на экране писалось «Ошибка соединения с базой данных». Написал хостеру, там подтвердили что большая нагрузка на MySQL и что-то с этим делайте, а пока перевели на тариф выше. Сразу же начал искать, что же делать и нашёл Вашу статью, которая уменьшила базу в 5 раз. Плагин который сначала не хотел работать, всё таки заработал, но основная проблема, убрать лишние запросы, так и не была решена. У меня уже стоит плагин WP Super Cache, но он кеширует страницы, а не запросы к БД. И вот я до четырёх часов утра искал плагин, который мне сможет помочь с запросами и нашёл. WP File Cache кеширует запросы, количество запросов и МБ памяти, уменьшается в разы. На страницах где до этого было 40 запросов и 35МБ, теперь запросов 9 и 12МБ. Единственное, скорость загрузки вроде чуток увеличилось, но незначительно, учитывая что скорость загрузки страниц у меня, в среднем 0,15-0,5 секунды. Может кому то данная информация будет интересна.
-
7 декабря 2013 15:41
выше указанные действия могут повлиять на работу плагина nrelate-flyout ?
От того, насколько хорошо оптимизированы запросы к базе данных mySQL, сильно зависит степень нагрузки на сервер, а значит и скорость загрузки сайта. Разгрузить сервер и уменьшить время загрузки вашего сайта поможет оптимизация mySQL запросов.

Зачем оптимизировать запросы к базе данных
Владельцы сайтов, находящихся под управлением самописных систем администрирования просто обязаны хорошо понимать, какие запросы к базе данных выполняются быстро и легко, а какие сильно повышают нагрузку на сервер и значительно замедляют скорость загрузки сайта.
Вникнуть в суть дела не помешает и тем веб-мастерам, которые используют известные системы администрирования и любят подключать всевозможные плагины сторонних разработчиков, а так же кастомизировать темы под себя, к примеру, на самой популярной бесплатной CMS – WordPress.
 Некоторые действия можно выполнить разными способами, например, посчитать количество найденных в таблице записей можно при помощи функции mysql_num_rows (но делать этого не рекомендуется), а можно и при помощи конструкции SELECT COUNT(). Нами лично было проведено исследование, в котором мы создали огромную таблицу данных, содержащую несколько сотен тысяч записей и весящую более одного гигабайта, а затем попробовали посчитать количество строк указанными способами.
Некоторые действия можно выполнить разными способами, например, посчитать количество найденных в таблице записей можно при помощи функции mysql_num_rows (но делать этого не рекомендуется), а можно и при помощи конструкции SELECT COUNT(). Нами лично было проведено исследование, в котором мы создали огромную таблицу данных, содержащую несколько сотен тысяч записей и весящую более одного гигабайта, а затем попробовали посчитать количество строк указанными способами.
Результат был виден невооруженным глазом, ведь в случае использования mysql_num_rows, страница подвисала секунд на 5, после чего выводился результат. Во втором же случае мы получали результат в виде количества записей в таблице практически моментально. Нам даже не пришлось замерять время загрузки скрипта при помощи микротаймера, ведь результат был более чем очевиден.
То же самое касается и других конструкций. Некоторые операции с базой данных можно выполнить двумя, тремя, четырьмя и более способами и каждый из них будет отличаться именно скоростью, в то время как результат во всех случаях будет одинаково верным.
Как оптимизировать запросы к базе данных
Для того, чтобы понять, как именно оптимизировать запросы и какие конструкции работают быстрее, а какие медленней, мы снова проведем небольшой опыт и сделаем это прямо сейчас.
Нам придется обратиться за помощью к интерфейсу популярного и очень удобного phpmyadmin. Для того, чтобы начать, нам нужно выбрать одну из имеющихся баз данных и создать в ней тестовую таблицу. Ее название в нашем случае будет довольно банальным – test.
CREATE TABLE `test` (`ID` INT NOT NULL AUTO_INCREMENT , `TITLE` VARCHAR(100) CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL , `ANNOUNCEMENT` TEXT CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL , `TEXT` TEXT CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL , PRIMARY KEY (`ID`)) ENGINE = MYISAM ;
 Теперь, когда тестовая таблица у нас уже есть, нужно наполнить ее абстрактными данными. Как видно из структуры только что созданной нам таблицы, нам потребуются следующие данные для заполнения:
Теперь, когда тестовая таблица у нас уже есть, нужно наполнить ее абстрактными данными. Как видно из структуры только что созданной нам таблицы, нам потребуются следующие данные для заполнения:
- Заголовок
- Анонс
- Полный текст
За абстрактными текстами мы по привычке пойдем на сервис Яндекс.Рефераты , созданный как раз для подобных целей. Нам посчастливилось наткнуться на тему «Торсионный фотон в XXI веке», ее и возьмем.
 Мы указали выбранную случайно тему в качестве заголовка, в качестве анонса взяли один средненький абзац текста, а в роли полного текста статьи у нас с вами будет текст, длиной в 4000 символов с пробелами. Для подсчета количества символов в тексте мы воспользовались нашим собственным сервисом и вам рекомендуем считать именно в нем, т.к. там есть возможность учитывать пробелы или нет.
Мы указали выбранную случайно тему в качестве заголовка, в качестве анонса взяли один средненький абзац текста, а в роли полного текста статьи у нас с вами будет текст, длиной в 4000 символов с пробелами. Для подсчета количества символов в тексте мы воспользовались нашим собственным сервисом и вам рекомендуем считать именно в нем, т.к. там есть возможность учитывать пробелы или нет.
Получившийся запрос мы сюда копировать не будем, т. к. это будет более 4000 символов не уникального текста, взятого у самого Яндекса, что довольно дерзко, да и вам это тоже не нужно. Лучше мы набросаем простейший цикл на PHP, который быстро добавит в базу данных столько записей, сколько мы захотим. Для начала это будет 100000 статей.
Чем меньше запросов к базе данных, тем лучше
Уже на этом этапе мы покажем вам распространенную ошибку, которую сами же сейчас специально и допустим.
For($i=1;$i<100000;$i++) { mysql_query("INSERT INTO `test` (`ID`, `TITLE`, `ANNOUNCEMENT`, `TEXT`) VALUES (NULL, "Заголовок", "Анонс", "Полный текст")"); }
В качестве запроса мы вставили скопированный из phpmyadmin код, который был отображен на экране после единичного добавления первой статьи вручную. Сразу хочется отметить, что таким образом запросы к базе данных строить не стоит. Мы это сделали лишь потому, что нам просто нужно было быстро наполнить таблицу случайными данными, а этот запрос пишется быстрее, чем тот, который более оптимален. В этом цикле у нас получилось 99999 отдельных обращений к базе данных (первое мы осуществили вручную из phpmyadmin), что является очень плохим тоном.
Гораздо более правильным решением будет сделать ту же операцию, использовав всего одно обращение к базе данных, перечислив все строки через запятую.
INSERT INTO `test` (`ID`, `TITLE`, `ANNOUNCEMENT`, `TEXT`) VALUES (NULL, "Заголовок", "Анонс", "Полный текст"), (NULL, "Заголовок", "Анонс", "Полный текст"), (NULL, "Заголовок", "Анонс", "Полный текст"), …
Если вернуться к нашему первому способу, то он бы выглядел вот так:
INSERT INTO `test` (`ID`, `TITLE`, `ANNOUNCEMENT`, `TEXT`) VALUES (NULL, "Заголовок", "Анонс", "Полный текст") INSERT INTO `test` (`ID`, `TITLE`, `ANNOUNCEMENT`, `TEXT`) VALUES (NULL, "Заголовок", "Анонс", "Полный текст") INSERT INTO `test` (`ID`, `TITLE`, `ANNOUNCEMENT`, `TEXT`) VALUES (NULL, "Заголовок", "Анонс", "Полный текст") …
Чувствуете разницу? Вариант, в котором используется только одно обращение к базе данных и является оптимальным. Скорость работы этих двух способов, приводящих к одному и тому же результату отличается в разы и видна без всяких измерений невооруженным глазом, поверьте, это действительно так.
Производить выборку только необходимых скрипту полей
Здесь все очень просто – та или иная функция нуждается в определенных данных из целевой таблицы. Очень часто оказывается так, что нужно вытащить вообще все поля, особенно, если таблица довольно большая и этих полей больше 10.
SELECT * FROM `test`
В данном запросе звездочка означает то, что будут извлечены данные из всех полей таблицы test. А что, если этих полей в таблице 20-30 штук или больше? Скрипту скорее всего необходимы лишь некоторые из них, а все остальные, которые не будут никак использоваться, будут выбраны зря. Такая операция будет выполняться медленнее, чем если бы вы указали через запятую только те поля, которые вам действительно нужны в данный момент.
SELECT `ID`, `TITLE` FROM `test`
В этом примере мы вообще не будем касаться анонса и полного текста статьи, что заметно ускорит работу скрипта. Таким образом мы с вами делаем вывод, что под оптимизацией запросов к базе данных понимается так же конкретное указание необходимых полей в запросах и отказ от универсальности в виде звездочки.
Объединение нескольких запросов в один
Мы уже с вами обсудили, что хорошая оптимизация работы с mySQL подразумевает использование минимально возможного количества запросов и привели пример с добавлением данных в таблицу.
 Помимо добавления, данный прием можно и нужно использовать и при выборке данных. А теперь давайте приведем самый простой пример. Представьте себе, что у в вашей базе данных есть две таблицы – первая таблица хранит в себе информацию о зарегистрированных пользователях, а вторая содержит статьи, написанные этими пользователями.
Помимо добавления, данный прием можно и нужно использовать и при выборке данных. А теперь давайте приведем самый простой пример. Представьте себе, что у в вашей базе данных есть две таблицы – первая таблица хранит в себе информацию о зарегистрированных пользователях, а вторая содержит статьи, написанные этими пользователями.
Допустим, вам нужно вывести на экран какую-нибудь случайную статью, а снизу подписать ее именем автора. Связь таблиц между собой в данном случае очевидна и происходит по идентификатору пользователя, т. е. ID пользователя в таблице users должен соответствовать полю USER_ID в таблице posts. Данная связь является стандартной и должна быть понятна всем, без исключения.
Итак, чтобы выбрать случайную статью, вы пишете запрос следующего вида:
$rs_post = mysql_query("SELECT `ID`, `USER_ID`, `TITLE`, `TEXT` FROM `posts` ORDER by RAND() LIMIT 1");
Из таблицы posts случайным образом выберется одна статья. После чего наши действия будут иметь примерно такой вид:
$row_post = mysql_fetch_assoc($rs_post); $userID = $row_post["USER_ID"];
Теперь переменная $userID содержит идентификатор пользователя, являющегося автором этой статьи и для того, чтобы получить его данные, например NAME (имя) и SURNAME (фамилию), вы будете обращаться к таблице users и запрос будет выглядеть примерно так:
$rs_user = mysql_query("SELECT `NAME`, `SURNAME` FROM `users` WHERE `ID` = "".$row_post["USER_ID"]."" LIMIT 1");
Кстати, не забывайте обрамлять одинарными кавычками переменные в запросах, особенно это нужно делать, когда данные поступают извне, при помощи GET или POST. Это создаст дополнительное препятствие для злоумышленников и является одной из мер, направленных на защиту от SQL-инъекций . Итак, вернемся к нашему примеру. После того, как запрос к базе данных был сделан, далее все просто – получаем имя и фамилию и выводим в качестве подписи к статье. Задача выполнена.
Но эти два запроса можно оптимизировать, превратив в один. Для этого мы воспользуемся конструкцией LEFT JOIN:
SELECT `posts`.`ID`, `posts`.`USER_ID`, `posts`.`TITLE`, `posts`.`TEXT`, `users`.`NAME`, `users`.`SURNAME` FROM `posts` LEFT JOIN `users` ON `posts`.`USER_ID` = `users`.`ID` ORDER by RAND() LIMIT 1
Как видите, ничего сложного в приведенной конструкции нет и все интуитивно понятно. Единственное, на что хочется обратить ваше внимание – это явное указание таблиц в паре с полями, т. к. идет выборка сразу из нескольких таблиц. Если же названия каких-то полей совпадают, то следует использовать так называемые mySQL алиасы , чтобы потом не путаться при выводе результата.
Заключение
 Как видите, оптимизировать запросы к базе данных можно и нужно. Если вы думаете, что раз у вас все и так быстро работает, то нет смысла что-либо менять, подождите, когда база данных вашего сайта вырастет в несколько раз, а вместе с этим вырастет и посещаемость. Большая посещаемость подразумевает более частые одновременные обращения к базе данных, размер которой также влияет на скорость выполнения операций.
Как видите, оптимизировать запросы к базе данных можно и нужно. Если вы думаете, что раз у вас все и так быстро работает, то нет смысла что-либо менять, подождите, когда база данных вашего сайта вырастет в несколько раз, а вместе с этим вырастет и посещаемость. Большая посещаемость подразумевает более частые одновременные обращения к базе данных, размер которой также влияет на скорость выполнения операций.
Плохая оптимизация запросов может обнаружиться чуть позже, когда сайт достаточно разрастется, а со временем изменения вносить станет все тяжелей, ведь размеры файлов и количество функций только прибавляется. На сайт добавляют новые фичи, направленные на удобство пользователей. Иными словами, если дело дойдет до определенной точки кипения, можно уже и концов не сыскать и чтобы оптимизировать все обращения к базе данных, раскиданные по сотням файлов, потребуется несколько дней, а может и недель. Поэтому лучше сразу стараться делать хорошо, чтобы не создавать себе лишних проблем в будущем.
Иногда, формируя запрос, вы уже знаете, вам нужна только одна уникальная строка в таблице. Вы можете сформировать выборку по уникальной записи. Или вы можете просто запустить проверку на существование любого количества записей, которые удовлетворяют вашему условию.
В таких случаях, использование метода LIMIT 1 может существенно увеличить производительность:
// существуют ли в базе данные людей из Калифорнии? // НЕТ, таких нет!: $r = mysql_query("SELECT * FROM user WHERE state = "California""); if (mysql_num_rows($r) > 0) { // ... прочий код } // Положительный ответ $r = mysql_query("SELECT 1 FROM user WHERE state = "California" LIMIT 1"); if (mysql_num_rows($r) > 0) { // ... прочий код }
2. Оптимизация работы с базой с помощью обработки кэша запросов
Большинство серверов MySQL поддерживают функцию кэширования запросов. Это один из наиболее эффективных методов повышения производительности, с которым движок базы данных справляется без проблем.
Когда один и тот же запрос выполняется несколько раз, то, результат будет получен из кэша. Без необходимости обрабатывать снова все таблицы. Это значительно ускоряет процесс.
// если кэш запросов НЕ поддерживается $r = mysql_query("SELECT username FROM user WHERE signup_date >= CURDATE()"); // кэш поддерживается! $today_date = date("Y-m-d"); $r = mysql_query("SELECT username FROM user WHERE signup_date >= "$today_date"");
3. Индексация полей поиска
Индексы предназначены не только для присвоения первичному или уникальному ключам. Если в таблице есть столбцы, по которым вы производите поиск, их практически в обязательном порядке следует индексировать.
Как вы понимаете, это правило также распространяется на часть строки поиска: такую как «last_name LIKE ‘% ‘». Когда поиск производится по началу строки, MySQL может использовать для этого столбца индексацию.
Вы также должны понимать, какие виды запросов не могут использовать обычные индексы. Например, при поиске слова (например, «WHERE post_content LIKE ‘%tomato%"»), применение обычного индекса вам ничего не даст. В таком случае лучше будет использовать поиск MySQL на полное соответствие или создать свой собственный индекс.
4. Индексирование и использование столбцов одинакового типа при объединении
Если ваше приложение содержит много запросов на объединение, необходимо убедиться, что столбцы в обеих таблицах, которые вы объединяете, проиндексированы. Это влияет на оптимизацию внутренних операций MySQL по объединению.
Кроме того, столбцы, которые объединяются, должны быть одинакового типа. Например, если вы объединяете столбец типа DECIMAL из одной таблицы и столбец типа INT из другой, MySQL не сможет использовать по крайней мере один из индексов.
Даже кодировка символов должна быть того же типа для соответствующих строк объединяемых столбцов.
// ищем компании, находящиеся в моем штате $r = mysql_query("SELECT company_name FROM users LEFT JOIN companies ON (users.state = companies.state) WHERE users.id = $user_id"); // оба столбца штатов должны быть проиндексированы // и они оба должны быть одинакового типа и иметь ту же кодировку символов для соответствующих строк // или MySQL придется сканировать всю таблицу полностью
5. По возможности не используйте запросы типа SELECT *
Чем больше данных в таблице обрабатывается при запросе, тем медленнее выполняется сам запрос. Время уходит на дисковые операции. Кроме того, когда сервер базы данных разделен с веб-сервером, возникают задержки при передаче данных между серверами.
// нежелательный запрос $r = mysql_query("SELECT * FROM user WHERE user_id = 1"); $d = mysql_fetch_assoc($r); echo "Welcome {$d["username"]}"; // лучше использовать следующий код: $r = mysql_query("SELECT username FROM user WHERE user_id = 1"); $d = mysql_fetch_assoc($r); echo "Welcome {$d["username"]}";
6. Пожалуйста, не используйте метод сортировки ORDER BY RAND()
Это один из тех приемов, которые на первых порах кажутся неплохими, и многие программисты-новички попадаются на эту удочку. Вы даже не представляете, какую ловушку расставляете сами себе же, как только начинаете использовать в запросах этот фильтр.
Если вам действительно нужно отсортировать некоторые строки в результатах поиска, то есть гораздо более эффективные способы сделать это. Допустим, что вам нужно добавить дополнительный код к запросу, но из-за данной ловушки вы не сможете этого сделать, что приведет к уменьшению эффективности обработки данных, по мере того, как база будет разрастаться в размерах.
Проблема в том, что MySQL будет выполнять операцию RAND () (которая использует вычислительные ресурсы сервера) перед сортировкой для каждой строки в таблице. При этом выбираться будет всего одна строка.
// какой код НЕ следует использовать: $r = mysql_query("SELECT username FROM user ORDER BY RAND() LIMIT 1"); // правильнее будет использовать следующий код: $r = mysql_query("SELECT count(*) FROM user"); $d = mysql_fetch_row($r); $rand = mt_rand(0,$d - 1); $r = mysql_query("SELECT username FROM user LIMIT $rand, 1");
Таким образом, вы выберете меньшее количество результатов поиска, после чего сможете применить метод LIMIT, описанный в пункте 1.
7. Используйте столбцы типа ENUM вместо VARCHAR
Столбцы типа ENUM очень компактны, а, следовательно, быстры в обработке. Внутри базы их содержание хранится в формате TINYINT , но они могут содержать и выводить любые значения. Поэтому в них очень удобно задавать определенные поля.
Если у вас есть некоторое поле, которое содержит несколько разных значений одного вида, то вместо столбцов типа VARCHAR лучше использовать ENUM. Например, это может быть столбец «Статус », который содержит только такие значения, как «активно », «неактивно », «ожидание », «срок действия истек » и т.д.
Существует даже возможность задать сценарий, при котором MySQL будет «предлагать» изменить структуру таблицы. Когда у вас есть поле типа VARCHAR, система может автоматически рекомендовать изменить формат столбца на ENUM. Это можно сделать с помощью вызова функции PROCEDURE ANALYSE() .
Используйте для хранения IP-адресов поля типа UNSIGNED INT
Многие разработчики создают для этих целей поля типа VARCHAR (15) , в то время как IP-адреса можно было бы хранить в базе в виде десятичных чисел. Поля типа INT предоставляют возможность хранить до 4 байта информации, и при этом для них можно задать фиксированный размер поля.
Вы должны удостовериться, что ваши колонки имеют формат UNSIGNED INT , поскольку IP-адрес задается 32-мя битами.
В запросах можно использовать параметр INET_ATON () для преобразования IP-адресов в десятичные числа, и INET_NTOA () — наоборот. PHP имеет и другие аналогичные функции long2ip () и ip2long () .
8. Вертикальное секционирование (разделение)
Вертикальное секционирование представляет собою процесс, когда структура таблицы разделяется по вертикали из соображений оптимизации работы с базой данных.
Пример 1: Допустим, у вас есть таблица пользователей, в которой в числе прочего содержатся их домашние адреса. Данная информация используется очень редко. Вы можете разделить вашу таблицу и хранить данные по адресам в другой таблице.
Таким образом, ваша основная таблица пользователей заметно уменьшится в размерах. А как вы знаете, меньшие таблицы, обрабатываются быстрее.
Пример 2: У вас в таблице есть поле «last_login » (последний логин). Оно обновляется каждый раз, когда пользователь входит в систему под своим именем пользователя. Но каждое изменение таблицы записывается в кэш запросов к этой таблице, который хранится на диске. Вы можете переместить это поле в другую таблицу, чтобы уменьшить количество обращений к вашей основной таблице пользователей.
Однако вы должны быть уверены в том, что обе таблицы, которые получились после секционирования, не будут в дальнейшем использоваться одинаково часто. В противном случае это существенно снизит производительность.
9. Меньшие столбцы – быстрее
Для движков баз данных дисковое пространство, пожалуй, самое узкое место. Поэтому хранить информацию более компактно, как правило, полезно с точки зрения производительности. Это уменьшает количество обращений к диску.
В MySQL Docs прописан ряд требований к хранению разных типов данных. Если ожидается, что таблица не будет содержать слишком большое количество записей, то нет причин хранить первичный ключ в полях типа INT, MEDIUMINT, SMALLINT , а в отдельных случаях даже TINYINT . Если в формате даты вам не нужны составляющие времени (часы: минуты), то используйте поля типа DATE вместо DATETIME.
Однако все же убедитесь, что на перспективу вы оставили себе достаточно пространства для развития. Иначе в какой-то момент может произойти что-то типа обвала.









Обзор Samsung Galaxy A7 (2017): не боится воды и экономии Стоит ли покупать samsung a7
Делаем бэкап прошивки на андроиде
Как настроить файл подкачки?
Установка режима совместимости в Windows
Резервное копирование и восстановление драйверов Windows