R 2 = r xy 2 , где r xy - коэффициент корреляции.
Например, значение R 2 = 0.83, означает, что в 83% случаев изменения х приводят к изменению y . Другими словами, точность подбора уравнения регрессии - высокая.
Рассчитывается для оценки качества подбора уравнения регрессии. Для приемлемых моделей предполагается, что коэффициент детерминации должен быть больше 50%. Модели с коэффициентом детерминации выше 80% можно признать достаточно хорошими. Значение коэффициента детерминации R 2 = 1 означает функциональную зависимость между переменными.
В случае нелинейной регрессии
коэффициент детерминации рассчитывается через этот калькулятор . При множественной регрессии, коэффициент детемрминации можно найти через сервис Множественная регрессия
В общем случае, коэффициент детерминации находится по формуле: или
Правило сложения дисперсий:
,
где - общая сумма квадратов отклонений;
- сумма квадратов отклонений, обусловленная регрессией («объясненная» или «факторная»);
- остаточная сумма квадратов отклонений.
С помощью данного онлайн-калькулятора рассчитывается коэффициент детерминации и проверяется его значимость (Пример решения).
Инструкция . Укажите количество исходных данных. Полученное решение сохраняется в файле Word . Также автоматически создается шаблон для проверки решения в Excel .
Линия регрессии является графическим отражением взаимосвязи между явлениями. Очень наглядно можно построить линию регрессии в программе Excel.
Для этого необходимо:
1.Открыть программу Excel
2.Создать столбцы с данными. В нашем примере мы будем строить линию регрессии, или взаимосвязи, между агрессивностью и неуверенностью в себе у детей-первоклассников. В эксперименте участвовали 30 детей, данные представлены в таблице эксель:
1 столбик — № испытуемого
2 столбик — агрессивность в баллах
3 столбик — неуверенность в себе в баллах

3.Затем необходимо выделить оба столбика (без названия столбика), нажать вкладку вставка , выбрать точечная , а из предложенных макетов выбрать самый первый точечная с маркерами .

4.Итак у нас получилась заготовка для линии регрессии — так называемая — диаграмма рассеяния . Для перехода к линии регрессии нужно щёлкнуть на получившийся рисунок, нажать вкладку конструктор, найти на панели макеты диаграмм и выбрать Ма кет9 , на нем ещё написано f(x)

5.Итак, у нас получилась линия регрессии. На графике также указано её уравнение и квадрат коэффициента корреляции

6.Осталось добавить название графика, название осей. Также по желанию можно убрать легенду, уменьшить количество горизонтальных линий сетки (вкладка макет , затем сетка ). Основные изменения и настройки производятся во вкладке Макет

Линия регрессии построена в MS Excel. Теперь её можно добавить в текст работы.
Для статистических моделей во многих случаях необходимо определить точность прогноза. Это производится с помощью специальных расчётов в Microsoft Excel, а использоваться будет коэффициент детерминации. Он обозначается как R^2.
Статистические модели можно разделить на качественные уровни в зависимости от коэффициента. От 0.8 до 1 относятся модели хорошего качества, модели достаточного качества имеют уровень от 0.5 до 0.8, а плохое качество имеет диапазон от 0 до 0.5.
Способ определения точности с помощью функции КВПИРСОН
В линейной функции коэффициент детерминации будет равен квадрату корреляционного коэффициента. Рассчитать его можно с помощью специальной функции. Для начала создадим таблицу с данными.
Потом нужно выбрать место, где будет показан результат расчёта и нажимаем на кнопку вставки функции.

После этого откроется специальное окно. Категорию нужно выбрать "Статистические" и выбираем КВПИРСОН. Эта функция позволяет определить коэффициент корреляции касательно функции Пирсона, соответственно квадратное значение коэффициента корреляции = коэффициенту детерминации.

После подтверждения действия, появится окно в котором нужно в полях выставить "Известные значения Х" и "Известные значения Y". Нажимаем мышкой поле "Известные значения Y" и в рабочем окне выделяем данные столбца Y. Аналогичное действие делаем и с другим полем выбирая данные уже с таблицы Х.

Как результат этих действий будет показано значение коэффициента детерминации в ячейке, которая ранее была выбрана для отображения результата.

Определение коэффициента детерминации если функция не является линейной.
Если функция нелинейная, то инструментарий Excel также позволяет рассчитать коэффициент с помощью инструмента "Регрессия". Его можно найти в пакете анализа данных. Но для начала нужно активировать этот пакет, перейдя в раздел "Файл" и в списке открыть "Параметры".

После этого можно увидеть новое окно, в котором нужно в меню выбрать "Надстройки", а в специальном поле по управлению надстройками выбираем "Надстройки Excel" и переходим к ним.

После перехода в надстройки Excel появится новое окно. В нём можно увидеть доступные для пользователя надстройки. Ставим галочку возле "Пакет анализа" и подтверждаем действие.

Найти его можно в разделе "Данные", после перехода в который нажимаем на "Анализ данных" в правой части экрана.

После его открытия, в списке выбираем "Регрессия"и подтверждаем действие.

После этого появится новое окно в котором можно производить настройки. Входные данные позволяют настроить значение интервалов Х и Y, достаточно выделить соответствующие ячейки аргументов другого аргумента. В поле уровня надежности можно выставить нужный показатель. Параметры вывода позволяют задать где будет показан результат. Если к примеру выбрать показ на текущем листе, то для начала нужно выбрать пункт "Выходной интервал" - и нажать на области основного окна где будет в будущем отображаться результат и координаты ячейки будут показаны соответствующем поле. В конце подтверждаем действие.

В рабочем окне появится результат. Так как мы вычисляем коэффициент детерминации, то в итогах нам нужен R-коэффициент. Если посмотреть на значение, то можно увидеть что оно относится к наилучшему качеству.

Способ определения коэффициента детерминации для линии тренда
Имея созданную таблицу с соответствующими значение, создаем график. Чтобы провести на нём линию тренда надо нажать на график, а именно на область где строится линия. Сверху в панели инструментов выбрать раздел "Макет", а в нём выбрать "Линия тренда". После этого в контексте данного примера в списке выбираем "Экспоненциальное приближение".

Линия тренда будет отображена на графике как кривая с черным цветом.

Для того чтобы показать коэффициент детерминации, нужно по черной кривой нажать правой кнопкой мыши и выбрать в списке "Формат линии тренда".

После этого появится новое окно. В нём нужно отметить флажком и выбрать нужное действие (показано на скриншоте). Благодаря этому коэффициент будет отображен на графике. После того как это было сделано, закрываем окно.

После закрытия окна формата линии тренда в рабочем окне можно увидеть значение коэффициента детерминации.

Если пользователю нужен другой типаж линии тренда, то в окне "Формат линии тренда" можно выбрать его. Не забыв задать его ранее при создании линии тренда в разделе "Макет" или в контекстном меню. Также не забываем ставить флажок для функции R^2.

Как результат можно увидеть изменение линии тренда и число достоверности.

После просмотра разных вариаций линий тренда, пользователь может определить наиболее подходящую для себя так как показатель достоверности может меняться в зависимости от выбора линии. Максимальный коэффициент это единица, что означает максимальную достоверность, однако не всегда можно достигнуть этого значения.
Так было рассмотрено несколько способов по нахождению коэффициента детерминации. Пользователь может выбрать наиболее оптимальный для своих целей.
Метод линейной регрессии позволяет нам описывать прямую линию, максимально соответствующую ряду упорядоченных пар (x, y). Уравнение для прямой линии, известное как линейное уравнение, представлено ниже:
ŷ — ожидаемое значение у при заданном значении х,
x — независимая переменная,
a — отрезок на оси y для прямой линии,
b — наклон прямой линии.
На рисунке ниже это понятие представлено графически:
На рисунке выше показана линия, описанная уравнением ŷ =2+0.5х. Отрезок на оси у — это точка пересечения линией оси у; в нашем случае а = 2. Наклон линии, b, отношение подъема линии к длине линии, имеет значение 0.5. Положительный наклон означает, что линия поднимается слева направо. Если b = 0, линия горизонтальна, а это значит, что между зависимой и независимой переменными нет никакой связи. Иными словами, изменение значения x не влияет на значение y.
Часто путают ŷ и у. На графике показаны 6 упорядоченных пар точек и линия, в соответствии с данным уравнением
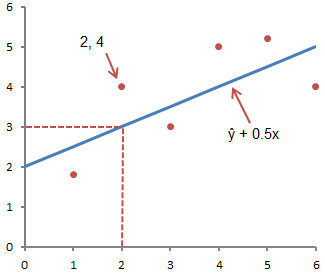
На этом рисунке показана точка, соответствующая упорядоченной паре х = 2 и у = 4. Обратите внимание, что ожидаемое значение у в соответствии с линией при х = 2 является ŷ. Мы можем подтвердить это с помощью следующего уравнения:
ŷ = 2 + 0.5х =2 +0.5(2) =3.
Значение у представляет собой фактическую точку, а значение ŷ — это ожидаемое значение у с использованием линейного уравнения при заданном значении х.
Следующий шаг - определить линейное уравнение, максимально соответствующее набору упорядоченных пар, об этом мы говорили в предыдущей статье, где определяли вид уравнения по .
Использование Excel для определения линейной регрессии
Для того, чтобы воспользоваться инструментом регрессионного анализа встроенного в Excel, необходимо активировать надстройку Пакет анализа . Найти ее можно, перейдя по вкладке Файл –> Параметры (2007+), в появившемся диалоговом окне Параметры Excel переходим во вкладку Надстройки. В поле Управление выбираем Надстройки Excel и щелкаем Перейти. В появившемся окне ставим галочку напротив Пакет анализа, жмем ОК.

Во вкладке Данные в группе Анализ появится новая кнопка Анализ данных.

Чтобы продемонстрировать работу надстройки, воспользуемся данными , где парень и девушка делят столик в ванной. Введите данные нашего примера с ванной в столбцы А и В чистого листа.
Перейдите во вкладку Данные, в группе Анализ щелкните Анализ данных. В появившемся окне Анализ данных выберите Регрессия , как показано на рисунке, и щелкните ОК.

Установите необходимыe параметры регрессии в окне Регрессия , как показано на рисунке:

Щелкните ОК. На рисунке ниже показаны полученные результаты:

Эти результаты соответствуют тем, которые мы получили путем самостоятельных вычислений в .
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
У = а 0 + а 1 х 1 +…+а к х к.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:


После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.


В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» - первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» - второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
Пример:



Теперь стали видны и данные регрессионного анализа.










Значение слова неудачный
Обзор Samsung Galaxy A7 (2017): не боится воды и экономии Стоит ли покупать samsung a7
Делаем бэкап прошивки на андроиде
Как настроить файл подкачки?
Установка режима совместимости в Windows