Целью тегов HTML является передача смысла документу. Не беспокойтесь о том, как ваша веб-страница выглядит. Сосредоточьтесь на значении каждого тега, который вы будете использовать.
В зависимости от написанного вами содержимого, вы можете выбрать подходящий элемент, соответствующий смыслу текста.
Диапазон элементов достаточно широк, чтобы он подходил и для материалов общего назначения (например, абзацы или списки) и для более конкретного содержимого, вроде
Структурные элементы: организация страницы
Структурные элементы позволяют организовать основные части вашей страницы. Они обычно содержат другие элементы HTML.
Вот что типичная веб-страница может в себя включать:
в качестве первого элемента страницы, который может включать в себя логотип и слоган; в качестве заголовка страницы;
в качестве основного содержимого страницы, вроде статьи блога;
Текстовые элементы: определение контента
Внутри структурных элементов вы обычно находите текстовые элементы, призванные определить цель вашего содержимого.
Вы, в основном, будете использовать:
Для абзацев;
-
для (неупорядоченных) списков;
-
для (упорядоченных) списков;
- для отдельных пунктов списка;
для цитат.
Строчные элементы: различный текст
Поскольку текстовые элементы могут быть длинными, но с разным содержанием, строчные элементы позволяют различать части текста.
Есть много строчных элементов, но вы обычно столкнётесь со следующими:
Просто читая этот код HTML, вы можете легко понять, что означает каждый элемент HTML .
Какие-то всякие разные штуки и некоторые выделенные и
даже важные слова.
Другой абзац.
Основной заголовок страницы
Подзаголовок
Однажды сказано
Общие элементы
Когда ни один семантический элемент не подходит для вашего содержимого, но вы всё ещё хотите вставить элемент HTML (в целях группирования или стилизации), то можете остановиться на одном из двух общих элементов:
- для блочных элементов;
- для строчных элементов.
Хотя эти элементы HTML на самом деле не несут какого-либо смысла , они пригодятся когда мы начнём использовать CSS.
Не заморачивайтесь на семантике
Существует около 100 семантических элементов HTML на выбор. Это много. Может оказаться непреодолимым пройтись по этому списку и выбрать соответствующий элемент для вашего контента.
Но не тратьте слишком много времени, беспокоясь об этом. Если вы будете придерживаться следующего списка на данный момент, этого будет достаточно.
Структурные Текстовые Строчные
Поскольку шифров в мире насчитывается огромное количество, то рассмотреть все шифры невозможно не только в рамках данной статьи, но и целого сайта. Поэтому рассмотрим наиболее примитивные системы шифрации, их применение, а так же алгоритмы расшифровки. Целью своей статьи я ставлю максимально доступно объяснить широкому кругу пользователей принципов шифровки \ дешифровки, а так же научить примитивным шифрам.
Еще в школе я пользовался примитивным шифром, о котором мне поведали более старшие товарищи. Рассмотрим примитивный шифр «Шифр с заменой букв цифрами и обратно».
Нарисуем таблицу, которая изображена на рисунке 1. Цифры располагаем по порядку, начиная с единицы, заканчивая нулем по горизонтали. Ниже под цифрами подставляем произвольные буквы или символы.
Рис. 1 Ключ к шифру с заменой букв и обратно.
Теперь обратимся к таблице 2, где алфавиту присвоена нумерация.
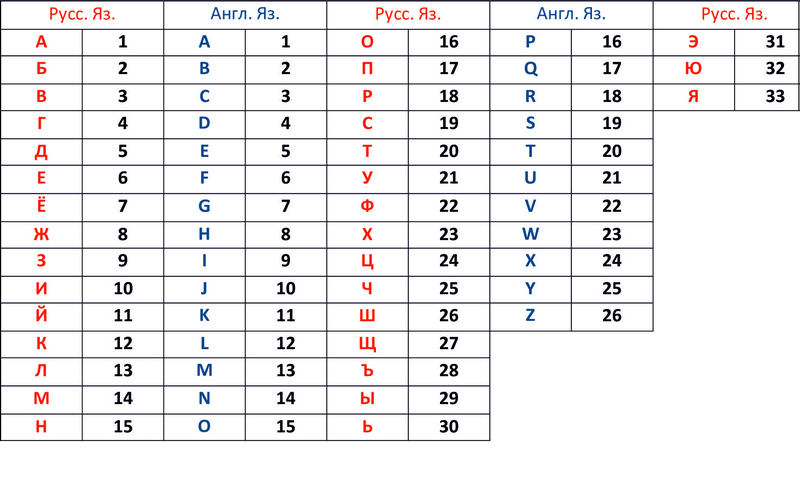
Рис. 2 Таблица соответствия букв и цифр алфавитов.
Теперь зашифруем словоК О С Т Е Р :
1) 1. Переведем буквы в цифры:К = 12, О = 16, С =19, Т = 20, Ё = 7, Р = 18
2) 2. Переведем цифры в символы согласно таблицы 1.
КП КТ КД ПЩ Ь КЛ
3) 3. Готово.
Этот пример показывает примитивный шифр. Рассмотрим похожие по сложности шрифты.
1. 1. Самым простым шифром является ШИФР С ЗАМЕНОЙ БУКВ ЦИФРАМИ. Каждой букве соответствует число по алфавитному порядку. А-1, B-2, C-3 и т.д.
Например слово «TOWN » можно записать как «20 15 23 14», но особой секретности и сложности в дешифровке это не вызовет.2. Также можно зашифровывать сообщения с помощью ЦИФРОВОЙ ТАБЛИЦЫ. Её параметры могут быть какими угодно, главное, чтобы получатель и отправитель были в курсе. Пример цифровой таблицы.

Рис. 3 Цифровая таблица. Первая цифра в шифре – столбец, вторая – строка или наоборот. Так слово «MIND» можно зашифровать как «33 24 34 14».
3. 3. КНИЖНЫЙ ШИФР
В таком шифре ключом является некая книга, имеющаяся и у отправителя и у получателя. В шифре обозначается страница книги и строка, первое слово которой и является разгадкой. Дешифровка невозможна, если книги у отправителя и корреспондента разных годов издания и выпуска. Книги обязательно должны быть идентичными.4. 4. ШИФР ЦЕЗАРЯ (шифр сдвига, сдвиг Цезаря)
Известный шифр. Сутью данного шифра является замена одной буквы другой, находящейся на некоторое постоянное число позиций левее или правее от неё в алфавите. Гай Юлий Цезарь использовал этот способ шифрования при переписке со своими генералами для защиты военных сообщений. Этот шифр довольно легко взламывается, поэтому используется редко. Сдвиг на 4. A = E, B= F, C=G, D=H и т.д.
Пример шифра Цезаря: зашифруем слово « DEDUCTION » .
Получаем: GHGXFWLRQ . (сдвиг на 3)Еще пример:
Шифрование с использованием ключа К=3 . Буква «С» «сдвигается» на три буквы вперёд и становится буквой «Ф». Твёрдый знак, перемещённый на три буквы вперёд, становится буквой «Э», и так далее:
Исходный алфавит:А Б В Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я
Шифрованный:Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В
Оригинальный текст:
Съешь же ещё этих мягких французских булок, да выпей чаю.
Шифрованный текст получается путём замены каждой буквы оригинального текста соответствующей буквой шифрованного алфавита:
Фэзыя йз зьи ахлш пвёнлш чугрщцкфнлш дцосн, жг еютзм ъгб.
5. ШИФР С КОДОВЫМ СЛОВОМ
Еще один простой способ как в шифровании, так и в расшифровке. Используется кодовое слово (любое слово без повторяющихся букв). Данное слово вставляется впереди алфавита и остальные буквы по порядку дописываются, исключая те, которые уже есть в кодовом слове. Пример: кодовое слово – NOTEPAD.
Исходный:A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
Замена:N O T E P A D B C F G H I J K L M Q R S U V W X Y Z6. 6. ШИФР АТБАШ
Один из наиболее простых способов шифрования. Первая буква алфавита заменяется на последнюю, вторая – на предпоследнюю и т.д.
Пример: « SCIENCE » = HXRVMXV7. 7. ШИФР ФРЕНСИСА БЭКОНА
Один из наиболее простых методов шифрования. Для шифрования используется алфавит шифра Бэкона: каждая буква слова заменяется группой из пяти букв «А» или «B» (двоичный код).a AAAAA g AABBA m ABABB s BAAAB y BABBA
b AAAAB h AABBB n ABBAA t BAABA z BABBB
c AAABA i ABAAA o ABBAB u BAABB
d AAABB j BBBAA p ABBBA v BBBAB
e AABAA k ABAAB q ABBBB w BABAA
f AABAB l ABABA r BAAAA x BABAB
Сложность дешифрования заключается в определении шифра. Как только он определен, сообщение легко раскладывается по алфавиту.
Существует несколько способов кодирования.
Также можно зашифровать предложение с помощью двоичного кода. Определяются параметры (например, «А» - от A до L, «В» - от L до Z). Таким образом, BAABAAAAABAAAABABABB означает TheScience of Deduction ! Этот способ более сложен и утомителен, но намного надежнее алфавитного варианта.8. 8. ШИФР БЛЕЗА ВИЖЕНЕРА.
Этот шифр использовался конфедератами во время Гражданской войны. Шифр состоит из 26 шифров Цезаря с различными значениями сдвига (26 букв лат.алфавита). Для зашифровывания может использоваться tabula recta (квадрат Виженера). Изначально выбирается слово-ключ и исходный текст. Слово ключ записывается циклически, пока не заполнит всю длину исходного текста. Далее по таблице буквы ключа и исходного текста пересекаются в таблице и образуют зашифрованный текст.
Рис. 4 Шифр Блеза Виженера
9. 9. ШИФР ЛЕСТЕРА ХИЛЛА
Основан на линейной алгебре. Был изобретен в 1929 году.
В таком шифре каждой букве соответствует число (A = 0, B =1 и т.д.). Блок из n-букв рассматривается как n-мерный вектор и умножается на (n х n) матрицу по mod 26. Матрица и является ключом шифра. Для возможности расшифровки она должна быть обратима в Z26n.
Для того, чтобы расшифровать сообщение, необходимо обратить зашифрованный текст обратно в вектор и умножить на обратную матрицу ключа. Для подробной информации – Википедия в помощь.10. 10. ШИФР ТРИТЕМИУСА
Усовершенствованный шифр Цезаря. При расшифровке легче всего пользоваться формулой:
L= (m+k) modN , L-номер зашифрованной буквы в алфавите, m-порядковый номер буквы шифруемого текста в алфавите, k-число сдвига, N-количество букв в алфавите.
Является частным случаем аффинного шифра.11. 11. МАСОНСКИЙ ШИФР
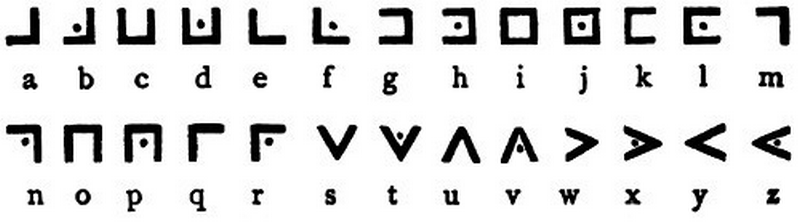

12. 12. ШИФР ГРОНСФЕЛЬДА
По своему содержанию этот шифр включает в себя шифр Цезаря и шифр Виженера, однако в шифре Гронсфельда используется числовой ключ. Зашифруем слово “THALAMUS”, используя в качестве ключа число 4123. Вписываем цифры числового ключа по порядку под каждой буквой слова. Цифра под буквой будет указывать на количество позиций, на которые нужно сдвинуть буквы. К примеру вместо Т получится Х и т.д.
T H A L A M U S
4 1 2 3 4 1 2 3T U V W X Y Z
0 1 2 3 4В итоге: THALAMUS = XICOENWV
13. 13. ПОРОСЯЧЬЯ ЛАТЫНЬ
Чаще используется как детская забава, особой трудности в дешифровке не вызывает. Обязательно употребление английского языка, латынь здесь ни при чем.
В словах, начинающихся с согласных букв, эти согласные перемещаются назад и добавляется “суффикс” ay. Пример: question = estionquay. Если же слово начинается с гласной, то к концу просто добавляется ay, way, yay или hay (пример: a dog = aay ogday).
В русском языке такой метод тоже используется. Называют его по-разному: “синий язык”, “солёный язык”, “белый язык”, “фиолетовый язык”. Таким образом, в Синем языке после слога, содержащего гласную, добавляется слог с этой же гласной, но с добавлением согласной “с” (т.к. язык синий). Пример:Информация поступает в ядра таламуса = Инсифорсомасацисияся поссотусупасаетсе в ядсяраса тасаласамусусаса.
Довольно увлекательный вариант.14. 14. КВАДРАТ ПОЛИБИЯ
Подобие цифровой таблицы. Существует несколько методов использования квадрата Полибия. Пример квадрата Полибия: составляем таблицу 5х5 (6х6 в зависимости от количества букв в алфавите).
1 МЕТОД. Вместо каждой буквы в слове используется соответствующая ей буква снизу (A = F, B = G и т.д.). Пример: CIPHER - HOUNIW.
2 МЕТОД. Указываются соответствующие каждой букве цифры из таблицы. Первой пишется цифра по горизонтали, второй - по вертикали. (A = 11, B = 21…). Пример: CIPHER = 31 42 53 32 51 24
3 МЕТОД. Основываясь на предыдущий метод, запишем полученный код слитно. 314253325124. Делаем сдвиг влево на одну позицию. 142533251243. Снова разделяем код попарно.14 25 33 25 12 43. В итоге получаем шифр. Пары цифр соответствуют букве в таблице: QWNWFO.Шифров великое множество, и вы так же можете придумать свой собственный шифр, однако изобрести стойкий шифр очень сложно, поскольку наука дешифровки с появлением компьютеров шагнула далеко вперед и любой любительский шифр будет взломан специалистами за очень короткое время.
Методы вскрытия одноалфавитных систем (расшифровка)
При своей простоте в реализации одноалфавитные системы шифрования легко уязвимы.
Определим количество различных систем в аффинной системе. Каждый ключ полностью определен парой целых чисел a и b, задающих отображение ax+b. Для а существует j(n) возможных значений, где j(n) - функция Эйлера, возвращающая количество взаимно простых чисел с n, и n значений для b, которые могут быть использованы независимо от a, за исключением тождественного отображения (a=1 b=0), которое мы рассматривать не будем.
Таким образом получается j(n)*n-1 возможных значений, что не так уж и много: при n=33 в качестве a могут быть 20 значений(1, 2, 4, 5, 7, 8, 10, 13, 14, 16, 17, 19, 20, 23, 25, 26, 28, 29, 31, 32), тогда общее число ключей равно 20*33-1=659. Перебор такого количества ключей не составит труда при использовании компьютера.
Но существуют методы упрощающие этот поиск и которые могут быть использованы при анализе более сложных шифров.
Частотный анализ
Одним из таких методов является частотный анализ. Распределение букв в криптотексте сравнивается с распределением букв в алфавите исходного сообщения. Буквы с наибольшей частотой в криптотексте заменяются на букву с наибольшей частотой из алфавита. Вероятность успешного вскрытия повышается с увеличением длины криптотекста.
Существуют множество различных таблиц о распределении букв в том или ином языке, но ни одна из них не содержит окончательной информации - даже порядок букв может отличаться в различных таблицах. Распределение букв очень сильно зависит от типа теста: проза, разговорный язык, технический язык и т.п. В методических указаниях к лабораторной работе приведены частотные характеристики для различных языков, из которых ясно, что буквы буквы I, N, S, E, A (И, Н, С, Е, А) появляются в высокочастотном классе каждого языка.
Простейшая защита против атак, основанных на подсчете частот, обеспечивается в системе омофонов (HOMOPHONES) - однозвучных подстановочных шифров, в которых один символ открытого текста отображается на несколько символов шифротекста, их число пропорционально частоте появления буквы. Шифруя букву исходного сообщения, мы выбираем случайно одну из ее замен. Следовательно простой подсчет частот ничего не дает криптоаналитику. Однако доступна информация о распределении пар и троек букв в различных естественных языках.Или подстановки. Составляется таблица однозначного соответствия алфавита исходного текста и кодовых символов, и в соответствии с этой таблицей происходит кодирование один в один. Чтобы раскодировать, нужно знать кодовую таблицу.
Существует большое число кодов, применяемых в разных областях человеческой жизни. Общеизвестные коды применяются по большей части для удобства передачи информации тем или иным способом. Если же кодовая таблица известна только передающему и принимающему, то получается довольно примитивный шифр, который легко поддаётся частотному анализу. Но если человек далёк от теории кодирования и не знаком с частотным анализом текста, то разгадать ему такие шифры довольно проблематично.
A1Z26
Простейший шифр. Называется A1Z26 или в русском варианте А1Я33. Буквы алфавита заменяются на их порядковые номера.
«NoZDR» можно зашифровать как 14-15-26-4-18 или 1415260418.
Азбука Морзе

Буквам, цифрам и некоторым знакам сопоставляется набор точек и тире, которые можно передавать по радио, звуком, стуком, световым телеграфом и отмашкой флажками. Более подробно про морзянку можно прочитать на страничке .
Шрифт Брайля
Брайль – это система тактильного чтения для слепых, состоящая из шеститочечных знаков, называемых ячейками. Ячейка состоит из трёх точек в высоту и из двух точек в ширину.
Различные брайлевские знаки формируются путем помещения точек в различные положения внутри ячейки.
Для удобства точки описываются при чтении следующим образом: 1, 2, 3 слева сверху вниз и 4, 5, 6 справа сверху вниз.

При составлении текста придерживаются следующих правил:
между словами пропускается одна ячейка (пробел);
после запятой и точки с запятой ячейка не пропускается;
тире пишется слитно с предыдущим словом;
перед числом ставится цифровой знак.

Кодовые страницы
В компьютерных квестах и загадках можно кодировать буквы в соответствии с их кодами в различных кодовых страницах - таблицах, используемых на компьютерах. Для кириллических текстов лучше всего пользоваться самыми распространёнными кодировками: Windows-1251, KOI8, CP866, MacCyrillic. Хотя для сложных шифровок можно выбрать и что-то более экзотичное.
Кодировать можно шестнадцатеричными числами, а можно и переводить их в десятичные. Например, буква Ё в KOI8-R имеет код B3 (179), в CP866 - F0 (240), а в Windows-1251 - A8 (168). А можно буквам в правых таблицах искать соответствие в левых, тогда текст получится набранным «кракозябрами» типа èαᬫº∩íαδ (866→437) или Êðàêîçÿáðû (1251→Latin-1).
Вот здесь https://www.artlebedev.ru/tools/decoder/advanced/ есть неплохой раскодировщик таких зашифрованных текстов:)



Масонский шифр
Масонский шифр известен также под названием «пигпен» (Pigpen) или «крестики-нолики». Этот шифр представляет собой простой шифр замены, в котором каждой букве алфавита соответствует графический символ, вычисляемой по одной из приведённых ниже сеток.

Чтобы зашифровать определённую букву при помощи этого шифра, нужно сначала определить место, где эта буква находится в одной из четырёх сеток, а затем нарисовать ту часть сетки, которая окружает эту букву. То есть, как-то так:
Если знать ключ (то, как буквы расположены в сетках), то разгадать такую надпись довольно легко. А вот если буквы в сетках изначально расставлены по какому-то неизвестному правилу (с ключевым словом, поочерёдно или вообще случайно), то в этой ситуации всегда может помочь
Использование графических символов вместо букв не является большим препятствием для криптоанализа, и эта система идентична другим простым схемам моноалфавитного замещения. Благодаря своей простоте, данный шифр часто упоминается в детских книжках про шифрование, тайнопись и всякие другие шпионские штучки.
Точное время происхождения шифра неизвестно, но некоторые из найденных записей этой системы датируются XVIII веком. Вариации этого шифра были использованы орденом розенкрейцеров и масонами. Последние использовали его в своих тайных документах и переписках довольно часто, поэтому шифр и стали называть шифром масонов. Даже на надгробиях масонов можно увидеть надписи, использующие данный шифр. Похожая система шифрования использовалась во время гражданской войны в США армией Джорджа Вашингтона, а также заключенными в федеральных тюрьмах Конфедераций Штатов США.
Ниже приведены два (синий и красный) варианта заполнения сетки таких шифров. Буквы расположены парами, вторая буква из пары рисуется символом с точкой:

Авторские шифры
Шифров, где одному символу алфавита (букве, цифре, знаку препинания) соответствует один (реже больше) графический знак, придумано великое множество. Большинство из них придуманы для использования в фантастических фильмах, мультфильмах и компьютерных играх. Вот некоторые из них:
Пляшущие человечки
Один из самых известных авторских шифров подстановки - это « ». Его придумал и описал английский писатель Артур Конан Дойл в одном из своих произведений про Шерлока Холмса. Буквы алфавита заменяются символами, похожими на человечков в разных позах. В книге человечки были придуманы не для всех букв алфавита, поэтому фанаты творчески доработали и переработали символы, и получился вот такой шифр:

Алфавит Томаса Мора
А вот такой алфавит описал в своём трактате «Утопия» Томас Мор в 1516 году:

Шифр Билла Шифра из мультсериала "Гравити Фолз"

Джедайский алфавит из "Звёздных войн"

Инопланетянский алфавит из "Футурамы"

Криптонский алфавит Супермена

Алфавиты биониклов

Семантика кода HTML всегда является горячим вопросом. Некоторые разработчики стараются всегда писать семантический код. Другие критикуют догматичных приверженцев. А некоторые даже понятия не имеют о том, что это такое и зачем оно нужно. Семантика определяется в HTML в тегах, классах, ID, и атрибутах, которые описывают назначение, но не задают точно содержание, которое в них заключено. То есть речь идет о разделении содержания и его формата.
Начнем с очевидного примера.
Плохая семантика кода
Заголовок статьиА авторИнко Гнито.Хорошая семантика кода
Заголовок статьи
Текст статьи, который кем-то написан. Инко Гнито - ее автор.
Вне зависимости от того, считаете ли вы, что HTML5 готов к использованию или нет, наверняка использование тега
в данном случаем будет более привлекательным, чем обычный с указанием класса. Название статьи становится заголовком, содержание становится параграфом, а выделенный жирным шрифтом текст становится тегом .Но не все так четко представляется тегами HTML5. Давайте рассмотрим набор имен классов и разберемся с тем, отвечают ли они требованиям семантики.
Не семантический код. Это классический пример. Каждая рабочая среда CSS для модульной сетки использует такого типа имена классов для определения элементов сетки. Будет ли это "yui-b", "grid-4", или "spanHalf" - такие имена ближе к заданию разметки, чем к описанию содержания. Однако их использование в большинстве случаев неизбежно при работе с шаблонами модульных сеток.
Семантический код. Нижний колонтитул (footer ) приобрел устойчивое значение в веб дизайне. Это нижняя часть страницы, которая содержит такие элементы как повторяющаяся навигация, права использования, информацию об авторе и так далее. Данный класс определяет группу для всех этих элементов без их описания.
Если вы перешли к использованию HTML5, то лучше применять элемент
Не семантический код. Он точно определяет содержание. Но почему текст должен быть большим? Чтобы выделяться среди другого более мелкого текста? "standOut " (выделение) больше подходит в данном случае. Вы можете решить изменить стиль для выделяющего текста, но ничего не делать с его размером, и в таком случаем название класса может привести вас в замешательство.
Семантический код. В данном случае речь идет об определении уровня важности элемента в интерфейсе приложения (например, параграфа или кнопки). Элемент с более высоким уровнем может иметь яркие цвета и больший размер, а элементы с низким уровнем могут содержать больше содержания. Но точного определения стилей в данном случае нет, поэтому код является семантическим. Данная ситуация очень похожа на использование тегов
,
,
, и так далее, но к другим элементам интерфейса.
Семантический код. Если бы каждое имя класса можно было так четко определить! В данном случае мы имеем описание раздела, который имеет содержание, назначение которого легко описать, также как и "tweets", "pagination" или "admin-nav".
Не семантический код. В данном случае речь идет о задании стиля для первого параграфа на странице. Такой прием используется для привлечения внимания читателей к материалу. Лучше использовать имя "intro", в котором отсутствует упоминание элемента. Но еще лучше использовать селектор для таких параграфов, например article p:first-of-type или h1 + p .
Не семантический код. Это очень обобщенное имя класса, которое используется для организации форматирования элементов. Но в нем нет ничего, чтобы касалось описания содержания. Различные теоретики семантики рекомендуют в таких случаях использовать имя класса наподобие "group". Вполне вероятно, что они правы. Так как данный элемент, несомненно, служит для группирования нескольких других элементов, и рекомендуемое название будет лучше описывать его назначение без погружения в детали.
Не семантический код. Слишком детальное описание формата содержания. Лучше подобрать другое имя, которое будет описывать содержание, а не его формат.
Семантический код. Класс очень хорошо описывает статус содержания. Например, сообщение об успешном завершении операции может иметь совершенно другой стиль от сообщения об ошибке.
Не семантический код. В данном примере имеется попытка задать определение формата содержания, а не его назначения. "plain-jane" очень похоже на "normal" или "regular". Идеальный код CSS должен быть написан так, чтобы не возникало необходимости в именах класса наподобие "regular", которые описывают формат содержания.
Не семантический код. Такого типа классы обычно используются для определения элементов сайта, которые не должны включаться в цепочку ссылок. В данном случае лучше использовать что-то наподобие rel=nofollow для ссылок, но не класс для всего содержания.
Не семантический код. Здесь имеется попытка описать формат содержания, а не его назначение.
Но...
Допустим, что у вас на сайте есть две статьи. И вы желаете задать им разные стили. "Обзоры фильмов" будут иметь голубой фон, а "Горячие новости" - красный фон и шрифт большего размера.
Один из способов решить задачу такой:
... ... Другой способ такой:
... ... Наверняка, если опросить нескольких разработчиков о том, какой код более соответствует требованиям семантики, большинство укажет на первый вариант. Он отлично соответствует материалу данного урока: описание назначение без ссылок на форматирование. А второй вариант указывает на формат ("blueBg" - имя класса, которое сформировано из двух английских слов, означающих "голубой фон"). Если вдруг будет принято решение поменять дизайн обзоров фильмов - например, сделать зеленый фон, то имя класса "blueBg" превратится в кошмар разработчика. А имя "movie-review" позволит абсолютно спокойно изменять стили оформления с сохранением отличного уровня поддержки кода.
Но никто не утверждает, что первый пример лучше во всех без исключения случаях. Допустим, что определённый оттенок синего используется во многих местах на сайте. Например, он является фоном для некоторой части нижнего колонтитула и областей в боковой панели. Вы можете воспользоваться следующим селектором:
Movie-review, footer > div:nth-of-type(2), aside > div:nth-of-type(4) { background: #c2fbff; }
Эффективное решение, так как цвет определяется только в одном месте. Но такой код становится сложным для поддержки, так как имеет длинный селектор, сложный для визуального восприятия. Также потребуются другие селекторы для определения уникальных стилей, что приведет к повторению кода. Или вы можете использовать другой подход и оставить их разделёнными:
Movie-review { background: #c2fbff; /* Определение цвета */ } footer > div:nth-of-type(2) { background: #c2fbff; /* И еще одно */ } aside > div:nth-of-type(4) { background: #c2fbff; /* И еще одно */ }
Такой стиль помогает сохранять CSS файл более организованным (разные области определяются в разных разделах). Но платой является повторение определений. Для больших сайтов определение одного и того же цвета может доходить до нескольких тысяч раз. Ужасно! Вариантом решения может быть использование класса по типу "blueBg" для определения цвета один раз и вставки его в HTML коде, когда требуется использовать данный дизайн. Конечно, его лучше назвать "mainBrandColor" или "secondaryFont", чтобы отвязаться от описания форматирования. Можно пожертвовать семантикой кода в пользу сохранения ресурсов.
И судя по тем рассуждениям, которые были в комментариях, мне бы хотелось прояснить один важный момент, который нужно понимать, прежде чем говорить о языке HTML и тегах, которые в нем используются.
Момент этот заключается в понимании такого важного понятия, как семантика кода . Давайте в этой заметке попытаемся разобраться с этим вопросом и зачем это все нужно.
Что такое семантика кода ?
Семантика (с лингвистической точки зрения) – это смысл, информационное содержание языка или отдельной его единицы.
Как мы знаем, структурными единицами языка HTML являются теги, они и являются теми самими отдельными единицами, которые несут смысл, информационное содержание.
Когда перед нами есть какая-то информация, которую нужно представить на веб-странице в Интернете, в первую очередь, мы должны объяснить компьютеру, какая часть этой информации, чем является. Не зная об этом, он просто не сможет правильно отобразить все содержимое.
Таким образом, когда мы создаем веб-страницу, с помощью языка HTML , мы объясняем компьютеру, какой элемент, какую роль должен играть на странице.
Мы должны понимать, что содержание каждого элемента веб-страницы должно быть заключено в теги, которые бы соответствовали их логическому и смысловому назначению.
Т.е. заголовки в тексте заключались бы в теги h 1-h 6, абзацы в теги p , списки в теги ul /ol (li ) и.т.д.
Код, который соответствует этим условиям, называют семантическим т.е. каждому элементу на веб-странице, соответствует правильное смысловое значение.
А теперь вопрос, можем ли мы заголовок на веб-странице, заключить в тег абзаца?
А почем нет? Конечно, можем. Многие скажут, но ведь при этом мы теряем оформление, которое имеют заголовки h 1-h 6. Но, на самом деле, оформление здесь никакой роли не играет. С помощью стилей CSS , мы можем присвоить любому абзацу точно такое же оформление, которое было у элемента h 1-h 6.Вывод, который мы с вами должны сделать, исходя из этого, семантика кода и оформление это две разные вещи, которые не нужно путать между собой. Определенное оформление каждому тегу присваивается, но его можно легко изменить,а вот изменить семантическое значение этого тега уже нельзя.
Мы можем заключить заголовок в абзац, но при этом теряется семантичность кода и этот текст будет нести совершенно иной смысл.
Поэтому, прежде чем заключать элемент в какой-либо тег, желательно подумать, а какую функцию, смысл он несет на странице?
Возникает логичный вопрос, а зачем в таком случае вообще нужна семантика кода?
Зачем заголовки делать заголовками, абзацы делать абзацами, аббревиатуры делать аббревиатурами и.т.д.?
По моему мнению, есть несколько причин, которые помогут вам склониться в сторону семантического кода. Что нам дает семантическая разметка?
1) Информацию о том, как браузеру по умолчанию отображать тот или иной элемент на странице;
Например, мы знаем, что заголовок h 1, если не задавать ему никаких специальных стилей, отображается на странице размером 2em и жирным шрифтом. Но, по моему мнению это самая не существенная причина.
2) Семантический код лучше читается и воспринимается поисковыми системами;
Считается, что страница, которая имеет семантическую разметку, при прочих равных условиях, будет выдаваться выше в результатах выдачи поисковых систем, чем страница с несемантическим кодом.
2) Код более понятный для человека;
Согласитесь, что разобраться с кодом, где все четко прописано, что эта часть текста является абзацем, эта аббревиатурой, и.т.д. намного легче, чем с кодом, где вся информация идет одной сплошной структурой и не понятно, что хотел сказать автор.
3) Проще получить доступ к элементу и как следствие большая гибкость.
Делая код семантическим, вы сможете намного проще обращаться к этим элементам с помощью специальных средств, которые работают с элементами на веб-страницах, например, языки CSS , Javascript и др.
Если вы заключите все аббревиатуры на вашей странице в тег abbr , то в CSS , для того, чтобы все аббревиатуры на вашей странице стали красными достаточно будет просто прописать.
abbr {color :red ;}
Вместо того, чтобы в HTML выделять и прописывать это правило к каждой отдельно взятой аббревиатуре.
Это всего лишь один пример, которых можно привести массу.
По этим причинам нужно понимать, что семантический код просто дает нашему документу больше возможностей. Мы можем применять какие-то теги для улучшения семантики сайта и получать при этом большую функциональность, либо их не применять и не получать эти выгоды.
Дело ваше!
Вы должны сами для себя принять это решение.
Статьи по теме
Последние статьи-
 2024-04-21 01:43:53Почему Водафон идет по стопам МТС и вводит региональность?
2024-04-21 01:43:53Почему Водафон идет по стопам МТС и вводит региональность? -
 2024-04-19 01:45:08Антивирус Bitdefender: эффективный защитник Без вопросов
2024-04-19 01:45:08Антивирус Bitdefender: эффективный защитник Без вопросов
Выбор редакции-
2024-04-14 01:47:28Резервное копирование и восстановление драйверов Windows
Это может потребоваться как при переустановке Windows на старом компьютере, так и для переноса файлов и параметров со старого компьютера на новый....
-
2024-04-13 02:01:28Как на «Билайне» перейти на другой тариф: все способы
У абонентов мобильного оператора МТС из-за обилия очень заманчивых предложений своего оператора нередко возникает вопрос, как перейти на другой тариф...
-
2024-04-13 02:01:28Смартфоны Meizu Очень приятная Flyme
Meizu / Мейзу - один из ведущих китайских производителей смартфонов. Модели Мейзу неизменно входят в число самых продаваемых андроид-смартфонов в...
-
2024-04-13 02:01:28Как быстро узнать баланс на всех устройствах с сим картой мегафон
Ведь в первом случае абоненту будет возможно выполнять дополнительные действия, такие как перевод денег, другому абоненту, или начисляться пакеты...
-
2024-04-12 01:45:27Бесплатные программы для Windows скачать бесплатно
Обзор программы Dr.Web Dr. Web CureIt - бесплатная антивирусная утилита для лечения/удаления инфицированных объектов на персональном компьютере....








Значение слова неудачный
Обзор Samsung Galaxy A7 (2017): не боится воды и экономии Стоит ли покупать samsung a7
Делаем бэкап прошивки на андроиде
Как настроить файл подкачки?
Установка режима совместимости в Windows